CN100558411C - 腱生蛋白-c核酸配体 - Google Patents
腱生蛋白-c核酸配体 Download PDFInfo
- Publication number
- CN100558411C CN100558411C CNB2004100629077A CN200410062907A CN100558411C CN 100558411 C CN100558411 C CN 100558411C CN B2004100629077 A CNB2004100629077 A CN B2004100629077A CN 200410062907 A CN200410062907 A CN 200410062907A CN 100558411 C CN100558411 C CN 100558411C
- Authority
- CN
- China
- Prior art keywords
- nucleic acid
- tenascin
- artificial sequence
- rna
- selex
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images





Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/115—Aptamers, i.e. nucleic acids binding a target molecule specifically and with high affinity without hybridising therewith ; Nucleic acids binding to non-nucleic acids, e.g. aptamers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/54—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic compound
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/54—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic compound
- A61K47/547—Chelates, e.g. Gd-DOTA or Zinc-amino acid chelates; Chelate-forming compounds, e.g. DOTA or ethylenediamine being covalently linked or complexed to the pharmacologically- or therapeutically-active agent
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/54—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic compound
- A61K47/549—Sugars, nucleosides, nucleotides or nucleic acids
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
- A61P17/06—Antipsoriatics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B82—NANOTECHNOLOGY
- B82Y—SPECIFIC USES OR APPLICATIONS OF NANOSTRUCTURES; MEASUREMENT OR ANALYSIS OF NANOSTRUCTURES; MANUFACTURE OR TREATMENT OF NANOSTRUCTURES
- B82Y5/00—Nanobiotechnology or nanomedicine, e.g. protein engineering or drug delivery
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H19/00—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof
- C07H19/02—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof sharing nitrogen
- C07H19/04—Heterocyclic radicals containing only nitrogen atoms as ring hetero atom
- C07H19/06—Pyrimidine radicals
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H19/00—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof
- C07H19/02—Compounds containing a hetero ring sharing one ring hetero atom with a saccharide radical; Nucleosides; Mononucleotides; Anhydro-derivatives thereof sharing nitrogen
- C07H19/04—Heterocyclic radicals containing only nitrogen atoms as ring hetero atom
- C07H19/06—Pyrimidine radicals
- C07H19/10—Pyrimidine radicals with the saccharide radical esterified by phosphoric or polyphosphoric acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07H—SUGARS; DERIVATIVES THEREOF; NUCLEOSIDES; NUCLEOTIDES; NUCLEIC ACIDS
- C07H21/00—Compounds containing two or more mononucleotide units having separate phosphate or polyphosphate groups linked by saccharide radicals of nucleoside groups, e.g. nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/001—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof by chemical synthesis
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1048—SELEX
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/12—Transferases (2.) transferring phosphorus containing groups, e.g. kinases (2.7)
- C12N9/1241—Nucleotidyltransferases (2.7.7)
- C12N9/1276—RNA-directed DNA polymerase (2.7.7.49), i.e. reverse transcriptase or telomerase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/34—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving hydrolase
- C12Q1/37—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving hydrolase involving peptidase or proteinase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/531—Production of immunochemical test materials
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/531—Production of immunochemical test materials
- G01N33/532—Production of labelled immunochemicals
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/531—Production of immunochemical test materials
- G01N33/532—Production of labelled immunochemicals
- G01N33/535—Production of labelled immunochemicals with enzyme label or co-enzymes, co-factors, enzyme inhibitors or enzyme substrates
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/569—Immunoassay; Biospecific binding assay; Materials therefor for microorganisms, e.g. protozoa, bacteria, viruses
- G01N33/56983—Viruses
- G01N33/56988—HIV or HTLV
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/74—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving hormones or other non-cytokine intercellular protein regulatory factors such as growth factors, including receptors to hormones and growth factors
- G01N33/76—Human chorionic gonadotropin including luteinising hormone, follicle stimulating hormone, thyroid stimulating hormone or their receptors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2123/00—Preparations for testing in vivo
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/13—Decoys
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/317—Chemical structure of the backbone with an inverted bond, e.g. a cap structure
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/318—Chemical structure of the backbone where the PO2 is completely replaced, e.g. MMI or formacetal
- C12N2310/3183—Diol linkers, e.g. glycols or propanediols
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/321—2'-O-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/322—2'-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
- C12N2310/3517—Marker; Tag
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2541/00—Reactions characterised by directed evolution
- C12Q2541/10—Reactions characterised by directed evolution the purpose being the selection or design of target specific nucleic acid binding sequences
- C12Q2541/101—Selex
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/158—Expression markers
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B40/00—Libraries per se, e.g. arrays, mixtures
-
- F—MECHANICAL ENGINEERING; LIGHTING; HEATING; WEAPONS; BLASTING
- F02—COMBUSTION ENGINES; HOT-GAS OR COMBUSTION-PRODUCT ENGINE PLANTS
- F02B—INTERNAL-COMBUSTION PISTON ENGINES; COMBUSTION ENGINES IN GENERAL
- F02B75/00—Other engines
- F02B75/02—Engines characterised by their cycles, e.g. six-stroke
- F02B2075/022—Engines characterised by their cycles, e.g. six-stroke having less than six strokes per cycle
- F02B2075/027—Engines characterised by their cycles, e.g. six-stroke having less than six strokes per cycle four
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/005—Assays involving biological materials from specific organisms or of a specific nature from viruses
- G01N2333/08—RNA viruses
- G01N2333/15—Retroviridae, e.g. bovine leukaemia virus, feline leukaemia virus, feline leukaemia virus, human T-cell leukaemia-lymphoma virus
- G01N2333/155—Lentiviridae, e.g. visna-maedi virus, equine infectious virus, FIV, SIV
- G01N2333/16—HIV-1, HIV-2
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/005—Assays involving biological materials from specific organisms or of a specific nature from viruses
- G01N2333/08—RNA viruses
- G01N2333/15—Retroviridae, e.g. bovine leukaemia virus, feline leukaemia virus, feline leukaemia virus, human T-cell leukaemia-lymphoma virus
- G01N2333/155—Lentiviridae, e.g. visna-maedi virus, equine infectious virus, FIV, SIV
- G01N2333/16—HIV-1, HIV-2
- G01N2333/163—Regulatory proteins, e.g. tat, nef, rev, vif, vpu, vpr, vpt, vpx
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/475—Assays involving growth factors
- G01N2333/50—Fibroblast growth factors [FGF]
- G01N2333/503—Fibroblast growth factors [FGF] basic FGF [bFGF]
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/575—Hormones
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/575—Hormones
- G01N2333/62—Insulins
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/81—Protease inhibitors
- G01N2333/8107—Endopeptidase (E.C. 3.4.21-99) inhibitors
- G01N2333/811—Serine protease (E.C. 3.4.21) inhibitors
- G01N2333/8121—Serpins
- G01N2333/8125—Alpha-1-antitrypsin
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/90—Enzymes; Proenzymes
- G01N2333/914—Hydrolases (3)
- G01N2333/948—Hydrolases (3) acting on peptide bonds (3.4)
- G01N2333/95—Proteinases, i.e. endopeptidases (3.4.21-3.4.99)
- G01N2333/964—Proteinases, i.e. endopeptidases (3.4.21-3.4.99) derived from animal tissue
- G01N2333/96425—Proteinases, i.e. endopeptidases (3.4.21-3.4.99) derived from animal tissue from mammals
- G01N2333/96427—Proteinases, i.e. endopeptidases (3.4.21-3.4.99) derived from animal tissue from mammals in general
- G01N2333/9643—Proteinases, i.e. endopeptidases (3.4.21-3.4.99) derived from animal tissue from mammals in general with EC number
- G01N2333/96433—Serine endopeptidases (3.4.21)
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/90—Enzymes; Proenzymes
- G01N2333/914—Hydrolases (3)
- G01N2333/948—Hydrolases (3) acting on peptide bonds (3.4)
- G01N2333/95—Proteinases, i.e. endopeptidases (3.4.21-3.4.99)
- G01N2333/964—Proteinases, i.e. endopeptidases (3.4.21-3.4.99) derived from animal tissue
- G01N2333/96425—Proteinases, i.e. endopeptidases (3.4.21-3.4.99) derived from animal tissue from mammals
- G01N2333/96427—Proteinases, i.e. endopeptidases (3.4.21-3.4.99) derived from animal tissue from mammals in general
- G01N2333/9643—Proteinases, i.e. endopeptidases (3.4.21-3.4.99) derived from animal tissue from mammals in general with EC number
- G01N2333/96433—Serine endopeptidases (3.4.21)
- G01N2333/96441—Serine endopeptidases (3.4.21) with definite EC number
- G01N2333/96455—Kallikrein (3.4.21.34; 3.4.21.35)
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/90—Enzymes; Proenzymes
- G01N2333/914—Hydrolases (3)
- G01N2333/948—Hydrolases (3) acting on peptide bonds (3.4)
- G01N2333/966—Elastase
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/90—Enzymes; Proenzymes
- G01N2333/914—Hydrolases (3)
- G01N2333/948—Hydrolases (3) acting on peptide bonds (3.4)
- G01N2333/972—Plasminogen activators
- G01N2333/9726—Tissue plasminogen activator
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/90—Enzymes; Proenzymes
- G01N2333/914—Hydrolases (3)
- G01N2333/948—Hydrolases (3) acting on peptide bonds (3.4)
- G01N2333/974—Thrombin
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/90—Enzymes; Proenzymes
- G01N2333/914—Hydrolases (3)
- G01N2333/948—Hydrolases (3) acting on peptide bonds (3.4)
- G01N2333/976—Trypsin; Chymotrypsin
Abstract
本发明描述了鉴别和分离腱生蛋白-C(tenascin-C)核酸配体的方法。本发明包括通过SELEX方法鉴别的腱生蛋白-C的RNA配体。进一步包括检测表达腱生蛋白-C的生物组织是否存在疾病状况的方法。
Description
本申请是申请号为00810979.6、申请日为2000年1月28日、发明名称为“腱生蛋白-C核酸配体”的中国专利申请的分案申请。
技术领域
本发明描述的是腱生蛋白-C(tenascin-C)的高亲和力核酸配体。本文还描述了鉴别和制备腱生蛋白-C高亲和力配体的方法。本文使用的鉴别这种核酸配体的方法称作SELEX,即配体指数富集系统生成法(Systematic Evolution of Ligands by Exponential enrichment)。本发明进一步公开了腱生蛋白-C的高亲和力核酸配体。另外公开了腱生蛋白-C的RNA配体。本发明还包括含嘌呤和嘧啶2’位置经化学修饰的核苷酸衍生物的寡核苷酸。另外公开了含2’F和2’OMe修饰的腱生蛋白-C RNA配体。本发明的寡核苷酸是有用的诊断和/或治疗剂。
背景技术
腱生蛋白-C 1.1-1.5百万道尔顿,是主要存在于胞外基质中的六面体糖蛋白。腱生蛋白-C在胚胎发生、伤口愈合和肿瘤形成过程中表达,说明这种蛋白在组织重塑中发挥功能(Erickson和Bourdon(1989)细胞生物学综述年报5:71-92)。肿瘤形成过程也涉及组织重塑,和腱生蛋白-C在包括肺癌、乳腺癌、前列腺癌、和结肠癌、星形细胞瘤、胶质母细胞瘤、黑色素瘤、和肉瘤中的过表达(Soini等(1993)美国临床病理学杂志100(2):145-50;Koukoulis等(1991)人类病理学22(7):636-43;Borsi等(1992)国际癌症杂志52(5):688-92;koukoulis等(1993)显微细胞病理学杂志25(2):285-95;Ibrahim等(1993)人类病理学24(9):982-9;Riedl等(1998)结肠直肠疾病41(1):86-92;Tuominen和Kallioinen(1994)皮肤病理学杂志21(5):424-9;Natali等(1990)国际癌症杂志46(4):586-90;Zagzag等(1995)癌症研究55(4):907-14;Hasegawa等(1997)神经病理学报(柏林)93(5):431-7;Saxon等(1997)儿童病理实验室医学17(2):259-66;Hasegawa等(1995)人类病理学26(8):838-45)。另外,腱生蛋白-C在高度增殖的皮肤疾病中过表达,例如牛皮癣(Schalkwijk等(1991)英国皮肤学杂志124(1):13-20),及在动脉粥样硬化损伤中(Fukumoto等(1998)动脉粥样硬化血栓症杂志5(1):29-35;Wallner等(1999)循环99(10):1284-9)。结合腱生蛋白-C的放射性标记抗体在临床中用于肿瘤的显影和治疗(Paganelli等(1999)欧洲核酸医学杂志26(4):348-57;Paganelli等(1994)欧洲核酸医学杂志21(4):314-21;Bigner等(1998)临床肿瘤学杂志16(6):2202-12;Merlo等(1997)国际癌症杂志71(5):810-6)。
抗腱生蛋白-C的适体(aptamer)具有潜在的诊断和治疗癌症和动脉粥样硬化及治疗牛皮癣的用途。相对抗体而言,适体较小(7-20kDa),易于从血中清除,并且是化学合成的。从血中迅速清除对体内显影诊断很重要,适体的血液水平是阻碍显影的主要决定性背景。迅速从血液中清除对治疗也是很重要的,血液水平可能产生毒性。SELEX技术可以迅速分离适体,而化学合成可以方便的在特定位点将适体与不同的惰性和生物活性分子偶联。抗腱生蛋白-C的适体因此在肿瘤治疗或体内或回体显影诊断和/或输送各种用于治疗表达腱生蛋白-C的疾病的偶联腱生蛋白-C核酸配体的治疗剂中是有用的。
核酸的主要作用是储存信息,这一定理已存在多年。通过已知的配体指数富集系统生成法方法,术语SELEX程序,核酸不同于蛋白具有三维结构多样性这一点愈加清晰。SELEX程序是与目的分子高特异性结合的核酸分子的一种体外进化方法,而且在1990年6月申请的美国专利申请号07/536.428中有描述,发明名称是“配体指数富集系统生成法”,现已放弃。发明名称为“核酸配体”的美国专利5,475,096,和发明名称为“鉴别核酸配体的方法”的美国专利5,270,163(参见WO91/19813),均专门附于本文作参考文献。所有这些申请本文统称为SELEX专利申请,它们描述了完全新型的制备任何目的分子核酸配体的方法。SELEX程序提供了一类称为核酸配体或适体的产物,每一个有特定序列,并具有特异结合目的化合物和分子的功能。每一种SELEX鉴别的核酸配体是特定目的化合物和分子的特异性配体。SELEX程序的根据是这样的特定认识,核酸具有很强的形成多种二维和三维结构的能力并且其单体具有足够的化学通用性,其实际上可与任何单体或聚合物化合物偶联,用作配体(形成特异的结合对)。任何大小或组成的分子可以作为SELEX方法的鉴别对象。SELEX方法在高亲和力结合试验中的应用包括从候选寡核酸混合物中进行筛选和逐步重复结合、分离及扩增步骤,利用相同的常用筛选方法,实际上可以获得任何预期标准的结合亲和力和选择性。SELEX方法起始于核酸混合物,优选含有一部分随机序列,包括的步骤有使靶与混合物接触,接触条件应适于结合,分离与靶特异结合的核酸与未结合的核酸,解离核酸-靶复合物,扩增从核酸-靶复合物中解离的核酸,以产生配体富集的核酸混合物,然后再按照预期循环数完全重复结合、分离、解离等步骤产生靶分子高特异性高亲和力配体。
本发明人发现SELEX方法证明作为化合物的核酸能形成多种形状、大小和构型,并具有更宽广的结合能力及生物系统中的核酸所没有的其它功能。
修改基本的SELEX方法可以达成大量特定目的。例如美国专利申请07/960,093,1992年10月14日申请,现已放弃,和美国专利5,707,796,发明名称均是“以结构为基础进行核酸筛选的方法”,描述了联合使用SELEX程序和凝胶电泳筛选有特定结构特征的核酸分子,如弯曲的DNA。美国专利申请08/123,935,1993年9月17日申请,发明名称是“光筛选核酸配体”,现已放弃,美国专利5,763,177,发明名称是“配体指数富集系统生成法:光筛选核酸配体和溶液SELEX”和美国专利申请09/093,293,1998年6月8日申请,发明名称是“配体指数富集系统生成法:光筛选核酸配体和溶液SELEX”描述了以SELEX为基础方法筛选含有能够与目的分子结合和/或光耦联和/或光灭活的光反应基团的核酸配体。美国专利5,580,737,发明名称是“可以区分茶碱和咖啡因的高亲和力核酸配体”,描述了鉴别能够分辨极为相近的,可能不是多肽分子的高特异性核酸配体的方法,称作反向-SELEX。美国专利5,567,588,发明名称是“指数富集配体系统进化:溶液SELEX”描述了一种以SELEX为基础的方法,可以高效分离对目的分子有高亲和力和低亲和力的寡核苷酸。
SELEX方法包括含修饰核苷酸的高亲和力核酸配体的鉴别,该修饰使配体性质改善,诸如体内稳定性增强或输送性能提高。这种修饰的实例包括核糖和/或磷酸和/或碱基位置的化学替代。发明名称是“含修饰核苷酸的高亲和力核酸配体”的美国专利5,660,985描述了SELEX程序-鉴别含修饰核苷酸的核酸配体,详述了5-和2’-嘧啶化学修饰的核苷酸衍生物。美国专利5,580,737,见上,描述了含一个或多个2’-氨基(2’-NH2),2’-氟(2’-F),和/或2’-O-甲基(2’-OMe)核苷酸修饰的高特异性核酸配体。美国专利申请08/264,029,1994年,6月22日申请,发明名称是“制备已知和新型分子内2’亲核置换修饰核苷的新方法”,现已放弃,描述了含各种2’修饰嘧啶的寡核苷酸。
SELEX方法包括,如美国专利5,637,459,发明名称是“指数富集配体系统进化:嵌合SELEX”,和美国专利5,683,867,发明名称是“配体指数富集系统生成法:混合SELEX”分别所述的,将筛选的寡核苷酸与筛选的其它寡核苷酸及非寡核苷酸功能单位结合起来。这些申请将寡核苷酸的形状多样性和其它特性,及有效扩增和复制的特性与其它分子的目的特征结合起来。
SELEX方法进一步包括如美国专利申请08/434,465,1995年5月4日申请,发明名称是“核酸配体复合物”中所描述的,在诊断或治疗复合物中将核酸配体与亲脂复合物或非免疫原的、高分子化合物结合。上述每一个描述了基本SELEX程序的专利和申请其全文引入本文作参考。
发明内容
本发明描述了分离高特异性结合腱生蛋白-C的核酸配体的方法。本文进一步描述了腱生蛋白-C的核酸配体。还描述了腱生蛋白-C的高亲和力RNA配体。而且描述了腱生蛋白-C的2’-氟修饰嘧啶和2’OMe-修饰嘌呤RNA配体。本文使用的鉴别这些核酸配体的方法称作SELEX,是配体指数富集系统生成法的缩写。本文包括显示于表3和表4及图10中的配体。
本发明进一步包括检测可能含有表达腱生蛋白-C的疾病的生物组织中该疾病的存在的方法。本发明还进一步包括检测可能含有表达腱生蛋白-C的肿瘤的生物组织中该肿瘤的存在的方法。本发明进一步包括用作体内或回体(ex vivo)诊断剂的复合物。而且本发明还包括向表达腱生蛋白-C的疾病组织输送治疗或预防使用的治疗剂的方法。本发明还进一步包括向表达腱生蛋白-C的疾病组织输送用于治疗或预防的治疗剂时所用的复合物。
附图说明
图1显示结合U251细胞的细胞SELEX RNA库。
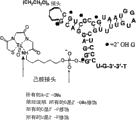
图2显示预测的适体TTA1和TTA1.NB二级结构。图中包括适体与螯合剂的缀合。所有的A是2’OMe修饰的。除非说明,所有的G是2’OMe修饰的。所有的C是2’F修饰的。
图3是注射Tc-99m标记的TTA1和TTA1.NB三小时后,小鼠体内U251肿瘤移植物的显影图。
图4显示静脉注射若丹明-Red-X-标记的TTA1三小时后取出的U251胶质母细胞瘤的荧光显微切片图。
图5显示Tc-99m与接头通过TTA15’G的连接方式。
图6描述了小鼠体内各种人肿瘤移植物摄取TTA1/GS7641 3小时,与摄取非结合的对照适体的比较结果,ID/g=注射剂量/克。
图7显示了使用DOTA或DTPA作为放射金属螯合剂的In-111标记的TTA1/GS7641三小时后的生物分布。
图8示出适体和DTPA的缀合。111In与DTPA螯合。
图9示出适体和DOTA的缀合。111In与DOTA螯合。
图10是推测的适体TTA1的二级结构图。图中包括适体与Tc-99m螯合剂的缀合。适体为Tc-99m标记形式。所有的A是2’OMe修饰的。所有的G,除说明外,是2’OMe修饰的。所有的C和U是2’F修饰的。
具体实施方式
本文所用的鉴别腱生蛋白-C核酸配体的主要方法称作SELEX程序,配体指数富集系统生成法的缩写,包括(a)使腱生蛋白-C与候选核酸混合物接触(b)根据与腱生蛋白-C的亲和力分离上述的候选混合物组分,及(c)扩增筛选出的分子产生对结合腱生蛋白-C亲和力相对较高的核酸序列富集的核酸复合物。本发明包括腱生蛋白-C的RNA配体。本发明进一步包括表3和4及图10中所示的腱生蛋白-C的特异RNA配体。尤其特别的是,本发明包括与表3和4及图10中所示的特异核酸配体具有相当大的同源性和基本相同的结合活性的核酸序列。相当大的同源性是指一级序列同源性大于70%,优选大于80%,更为优选大于90%,95%,或99%。本文中所述的同源性百分数是根据两条序列较短者中发现的与进行对比的序列中相同核苷酸残基对比的核苷酸百分数计算,为便于对比引入1个10个核苷酸间隔。结合腱生蛋白-C的能力基本相同是指在本文中描述的配体亲和力的一到两个数量级以内的亲和力。本领域一般技术人员都熟知,确定一段与此处描述的特异序列基本同源的序列是否具有与腱生蛋白-C相同的结合能力的方法。
表3和4和图10总述了腱生蛋白-C的核酸配体的序列同源性,其显示具有很小同源性的序列或无同源性的序列结合腱生蛋白-C的能力基本相同。由于这些原因,本发明还包括具有与表3和4以及图10中所示核酸配体基本相同假定结构或结构基元并能够与腱生蛋白-C结合的核酸配体。使用Zukerfold程序(参照Zuker(1989)科学244:48-52)进行序列同源性比较能够推测基本相同的结构或结构基元。正如本领域所知,也可使用其它计算机程序预测二级结构或结构基元。使用本领域所知的NMR或其它技术同样能够推测溶液中核酸配体基本相同的结构或结构基元或结合时的结构。
本发明进一步包括检测可能含有表达腱生蛋白-C的疾病的生物组织中该疾病的存在的方法,该方法包括(a)从候选核酸混合物中鉴别核酸配体,该核酸配体是腱生蛋白-C的配体,使用的鉴别方法为(i)将候选核酸混合物与腱生蛋白-C接触,其中相对于候选混合物与腱生蛋白-C的亲和力高的核酸可从剩余的候选混合物中分离出来;(ii)将高亲和力核酸与剩余的候选混合物分离开;(iii)扩增高亲和力核酸,产生富集结合腱生蛋白-C的亲和力和特异性均相对较高的核酸的核酸混合物,由此鉴别腱生蛋白-C的核酸配体;(b)将可用于体内诊断的标记物附着于在第(iii)步鉴别的核酸配体,形成标记物-核酸配体复合物;(c)将可能含有该疾病的组织暴露于该标记物-核酸配体复合物;以及(d)在该组织中检测标记物-核酸配体复合物的存在,从而鉴别表达腱生蛋白-C的疾病。
本发明的另一个目的是提供用于体内或回体诊断的含有一个或多个腱生蛋白-C核酸配体和一个或多个标记物的复合物。还进一步包括于本发明中的是输送治疗或预防表达腱生蛋白-C的疾病状况的治疗剂的方法。本发明还进一步包括用于输送治疗或预防表达腱生蛋白-C的疾病状况的治疗剂的复合物。
定义
本文使用的各种术语涉及本发明的多个方面。为了使本发明组成部分的描述清晰易懂,提供有下述定义:
正如本文所用的,“核酸配体”是指非天然存在的对靶有预期作用的核酸。核酸配体通常也称为“适体(aptamer)”。本发明的靶是腱生蛋白-C,因此该术语指腱生蛋白-C的核酸配体。预期作用包括,但不限制在,结合靶、催化改变靶、通过修饰/改变靶或靶功能活性的方式与靶反应、与靶共价偶联如在自杀抑制物中、促进靶与其它分子的反应。在优选实施例中,所述作用是与靶以特异性亲和力结合,这种靶是三维化学结构而不是通过主要决定于Watson/Crick碱基配对或三螺旋结合机制结合核酸配体的多核苷酸,其中核酸配体不是已知的与靶在生理条件下结合的核酸。从核酸混合物中鉴别核酸配体,这个核酸配体是腱生蛋白-C的配体,使用的鉴别方法包括:a)将候选核酸混合物与腱生蛋白-C接触,其中相对于候选混合物与腱生蛋白-C的亲和力高的核酸可从剩余的候选混合物中分离出来;b)将高亲和力核酸与剩余的候选混合物分离开;c)扩增高亲和力核酸,产生配体富集的核酸混合物(参照美国专利申请号08/434,425,1995年5月3日申请,现为美国专利5,789,157,此专利引入本文作参考)。
如本文所用的,“候选混合物”是序列不同的核酸混合物,从中可以筛选所需配体。候选混合物来源可以是天然存在的核酸或它们的片段、化学合成核酸、酶合成核酸或综合上述技术合成的核酸。优选实施例中,每一条核酸在随机区附近具有辅助扩增的固定序列。
如本文使用的,“核酸”是指DNA、RNA、单链或双链、及其任何化学修饰形式。修饰包括,但不局限在,向核酸配体碱基或整个核酸配体提供其它化学基团使加入额外电荷、极性、氢键、静电作用、和不定性。这种修饰包括,但不局限于,2’位置糖基化修饰、5位嘧啶修饰、8位嘌呤修饰、修饰外环氨基、4-硫尿苷代、5-溴或5-碘-尿嘧啶替代;基本骨架修饰、甲基化、异常碱基配对组合如胞嘧啶同一碱基之间和胍之间及类似情况。修饰还包括3’和5’修饰如帽子结构。
“SELEX”方法学涉及将与靶以预订方式反应的核酸配体的筛选过程,例如结合蛋白,与筛选出的核酸的扩增过程相结合。优化的重复循环筛选/扩增步骤能够使与靶反应最强的一种或少数核酸从含有极大量核酸的库中筛选出来。继续循环筛选/扩增程序直到获得预期筛选结果。本发明中,应用SELEX方法学获得了腱生蛋白-C的核酸配体。
SELEX方法学在SELEX专利申请中有描述。
“SELEX靶分子”或“靶”是指任何可与配体结合的目的复合物和分子。靶可以是蛋白、多肽、碳水化合物、多糖、糖蛋白、激素、受体、抗原、抗体、病毒、底物、代谢产物、过渡态类似物、辅助因子、抑制子、药物、染料、营养物等,没有限制。在本申请中,SELEX靶是腱生蛋白-C。
本文使用的“复合物”是指一个或多个腱生蛋白-C核酸配体与一个或多个标记物共价偶联形成的分子实体。在本发明的特定实施例中,复合物描述为A-B-Y,其中A是标记物;B任选包括接头;Y是腱生蛋白-C配体。
“标记物”在本文中是与腱生蛋白-C核酸配体直接或通过接头(一个或多个)或间隔物(一个或多个)形成复合物的分子实体或多个分子实体,标记物使得可以通过视觉或化学方法在体内或回体设置中检测到复合物。标记物的实例包括,但不局限于放射性物质,包括Tc-99m,Re-188,Cu-64,Cu-67,F-18,125I,131I,111In,32P;荧光团,包括荧光素,若丹明,得克萨斯红;上述荧光团的衍生物,包括若丹明-Red-X,磁性化合物,和生物素。
如本所用的,“接头”是分子实体,它通过共价键或非共价键作用连接两个或更多分子实体,能够使得分子之间有一定的空间分隔从而保留一个或多个分子实体的功能活性。接头还可以是已知的间隔物。接头的实例包括,但不局限在,图2所示的(CH2CH2O)6和己氨结构。
本文使用的“治疗的”,包括治疗和/或预防。在使用时,治疗涉及人和其它动物。
“共价键”是一对原子间形成的化学键。
“非共价键作用”是指分子实体通过这种作用而不是包括离子作用和氢键的共价键聚在一起。
在优选实施例中,本发明的核酸配体衍生于SELEX方法学。SELEX程序在美国专利申请系列号07/536,428,发明名称是“配体指数富集系统生成法”,现已放弃,美国专利5,475,096,发明名称是“核酸配体”及美国专利5,270,163,(参照WO 91/19813),发明名称是“鉴别核酸配体的方法”中有描述。这些申请,每一个都专门附于本文的参考文献中,总称为SELEX专利申请。
SELEX程序提供一类核酸分子产品,每一条核酸分子有特定序列,而且具有特异结合预期目的复合物和分子的活性。靶优选是蛋白,但也可以包括其它碳水化合物,肽聚糖和不同的小分子。SELEX方法学还能够通过与该生物结构完整部分的分子特异作用而用于生物结构打靶,如细胞表面或病毒。
SELEX程序最基本的形式可以定义为下列步骤:
1)制备序列不同的核酸候选混合物。候选混合物通常包括固定序列区(例如,每一个候选混合物组成在相同区段含有相同的序列)和随机序列区。所选的随机序列区可以是:(a)有助于下文所述的扩增步骤,或(b)模拟已知的结合靶的序列,或(c)增强候选混合物中特定结构排列的核酸的浓度。随机序列区可以是完全随机的(例如,任何一个位置上发现的碱基可能是四个中的一个)或仅仅是部分随机(例如,在任何一个位置上发现的碱基可以在0和100%间的任何水平选择)。
2)候选混合物在适合靶与候选混合物成员结合的条件下与靶接触。在这些环境下,靶和候选混合物核酸之间的反应可以认为是在靶和对靶有较强亲和力的核酸间形成核酸-靶配对。
3)从对靶亲和力较弱的核酸中分离对靶亲和力最强的核酸。因为只有极少数相当于最高亲和力核酸的序列(而且可能只有一个核酸分子)存在于候选混合物中,通常最好设置分离标准这样在分离过程中显著量的核酸保留在混合物中(约5-50%)。
4)分离过程中筛选的核酸具有相对较高的靶亲和力,然后通过扩增产生新的富集了具有相对较高靶亲和力的核酸候选混合物。
5)重复上述分离扩增步骤,新形成的候选混合物含有越来越少的特有序列,核酸对靶的平均亲和力程度通常会有所升高。分离扩增的极限,SELEX程序会产生含有一个或少数特定的对靶亲和力最高,代表原始候选混合物中的核酸分子的核酸候选混合物。
为了实现一些特殊目的,对基本SELEX方法进行了修改。例如,美国专利申请07/960,093,1992年10月14日申请,现已放弃,及美国专利5,707,796,发明名称均是“根据结构筛选核酸的方法”,描述了联合使用SELEX程序和凝胶电泳筛选有特定结构特征的核酸分子,如弯曲的DNA。美国专利08/123,935,1993年9月17日申请,发明名称是“核酸配体的光筛选”,现已放弃。美国专利5,763,177,发明名称是“配体指数富集系统生成法:核酸配体的光筛选和溶液SELEX”和美国专利申请09/093,293,1998年6月8日,发明名称是“配体指数富集系统生成法:核酸配体的光筛选和溶液SELEX”,都描述了以SELEX为根据的筛选含光活性基团能够结合和/或光耦联和/或光灭活靶的核酸配体。美国专利5,580,737,发明名称是“区分茶碱和咖啡因的高亲和力核酸配体”,描述了鉴别能够区分非常相近的分子的高特异性亲和力核酸配体的方法,称为反向-SELEX。美国专利5,567,588,发明名称是“配体指数富集系统生成法:溶液SELEX”,描述了以SELEX为基础的方法可以获得高效分离对靶有高亲和力和低亲和力的寡核苷酸。美国专利5,496,938,发明名称是:“HIV-RT和HIV-1 Rev的核酸配体”,描述了使用SELEX程序后获得改良核酸配体的方法。美国专利5,705,337发明名称是“配体指数富集系统生成法:化学-SELEX”,描述了配体与靶共价偶联的方法。
SELEX法包括鉴别含有使配体特性改良的修饰核苷酸的高亲和力核酸配体,例如体内稳定性增强或输送性能提高。这种修饰的实例包括在核糖和/或磷酸和/或碱基位置进行化学替代。SELEX鉴别含修饰核苷酸的核酸配体在美国专利5,660,985,发明名称是“含修饰核苷酸的高亲和力核酸配体”中有描述,该专利详述了含有5-和2’-化学修饰嘧啶核苷酸衍生物的寡核苷酸。美国专利5,637,459,如上所述,描述了含一个或多个2’-氨基(2’-NH2)、2’-氟基(2’-F),和/或2’-O-甲基(2’-OMe)修饰核苷酸的高特异核酸配体。美国专利申请08/264,029,1994年6月22日申请,发明名称是“制备已知和新型2’分子内亲核替代修饰核苷酸的新方法”,描述了含各种修饰嘧啶的寡核苷酸。
SELEX方法包括将筛选出的核苷酸与筛选的其它核苷酸和非核苷酸功能单位结合,正如美国专利5,637,459,发明名称是“配体指数富集系统生成法:嵌合SELEX”,和美国专利5,683,867,发明名称是“配体指数富集系统生成法:混合SELEX”分别描述的。这些申请能够将寡核苷酸的性状多样性和其它特性,及有效扩增和复制的特性与所需的其它分子的特性结合起来。
美国专利5,496,938描述了SELEX程序处理后获得改良核酸配体的方法。此专利,发明名称是“HIV-RT和HIV-1 Rev核酸配体”,专门附于本文的参考文献中。
美国专利申请号08/434,425,发明名称是“配体指数富集系统生成法;组织SELEX”,1995年5月3日申请,现是美国专利5,789,157,描述了鉴别组织大分子组分核酸配体的方法,包括癌细胞,和这种方法鉴别的核酸配体。此专利已专门附于本文的参考文献中。
在使用核酸进行诊断或治疗时可能碰到的潜在问题是体液中以磷酸二酯键存在的核酸在显示目的效应之前可能被胞内和胞外的酶如核酸内切酶和核酸外切酶降解。核酸配体的某种化学修饰能够提高核酸配体体内的稳定性或增强或辅助核酸配体的输送。参照,例如,美国专利申请08/117,991,1993年9月8日申请,现已放弃,和美国专利5,660,985,发明名称均是“含修饰核苷酸的高亲和力核酸配体”,已通过专门附于本文的参考文献中。本发明关注的核酸配体修饰包括,但不局限于,向核酸配体碱基或整个核酸配体提供其它化学基团使加入额外电荷、极性、氢键、静电作用、和不定性。这种修饰包括,但不局限于,2’位置糖基化修饰、5位密定修饰、8位嘌呤修饰、修饰外环氨基、4-硫尿苷代、5-溴或5-碘-尿嘧啶替代;基本骨架修饰、甲基化、异常碱基配对组合如胞嘧啶同一碱基之间和胍之间及类似情况。修饰还包括3’和5’修饰如帽子结构。本发明优选实施例中,核酸配体是在嘧啶残基糖分子上有2’-氟基(2’-F)修饰的RNA分子。
修饰可以在SELEX程序前后进行。SELEX程序前修饰产生SELEX靶特异性和体内稳定性增强的核酸配体。SELEX程序后修饰产生2’-OH核酸配体能够使体内稳定性增强而对核酸配体的结合能力无相反的影响。
其它修饰是本领域任何普通技术人员熟知的。这种修饰可以在SELEX程序之后(修饰上述鉴别的未修饰配体)或融合于SELEX程序中进行。
本发明中的核酸配体是通过SELEX方法学制备的,此方法学上文已有概述并在SELEX申请中授予权力,本文将它们附于本文的参考文献中。
本发明的腱生蛋白-C适体与腱生蛋白-C COOH末端的肝磷脂结合位点结合。
在本发明的特定实施例中,本文的腱生蛋白-C核酸配体可用于诊断目的并能用于病理状态的显影(如人肿瘤显影)。除诊断之外,腱生蛋白-C核酸配体可用于预后和检测腱生蛋白-C表达的病理状况。
诊断药剂只需要能够让使用者可以鉴别在特定位置出现的特定靶或其浓度。只要与靶形成的结合键足以引发用于诊断的阳性信号即可。本领域的熟练技术人员能够使用本领域熟知的方法用腱生蛋白-C核酸配体与标记物偶联显示核酸配体的出现。这种标记物能够用于某些诊断过程,诸如检测原发肿瘤和发生转移的肿瘤及动脉硬化损伤。本文的标记物实例是锝-99m和111In,然而,其它标记物如附加的放射性核素、磁性化合物、荧光团、生物素、及类似物可以与腱生蛋白-C核酸配体偶联,显影在体内或回体设定的表达腱生蛋白-C的疾病状态(例如,癌症,动脉硬化症,和牛皮癣)。标记物可以共价偶联于腱生蛋白-C核酸配体的多个位置,诸如碱基外环氨基基团、嘧啶核苷酸5-位、嘌呤核苷酸8-位,磷酸的羟基,或腱生蛋白-C核酸配体5’或3’末端的其它基团。在标记物是锝-99m或111In的实施例中,优选结合于磷酸基团的5’或3’羟基或修饰嘧啶的5位。在最优选的实施例中,标记物通过接头或不通过接头结合于磷酸基团的5’羟基。在另一个实施例中,标记物通过含5位原始氨基的嘧啶与核酸配体结合,并应用氨基与标记物连接。可以与标记物直接连接或使用接头。实施例中使用锝-99m或111In作为标记物,优选接头是如图10所示的己氨接头。
在其它实施例中,腱生蛋白-C核酸配体有助于向表达腱生蛋白-C的组织或器官输送治疗复合物(包括,但不限制在,细胞毒性复合物,免疫增强物质和用于治疗的放射性核素)。腱生蛋白-C可能表达的疾病状态包括,但不局限在,癌症、动脉硬化,和牛皮癣。本领域的熟练技术人员能够使用本领域熟知的程序选用腱生蛋白-C核酸配体与治疗复合物结合形成新的复合物。治疗复合物可以共价结合于腱生蛋白-C核酸配体的多个位置,诸如碱基的外环氨基、嘧啶核苷酸5-位、嘌呤核苷酸8-位、磷酸羟基,或腱生蛋白-C核酸配体5’或3’末端羟基或其它基团。在优选实施中,治疗剂结合于核酸配体5’氨基。可以直接与治疗剂结合或使用接头。在以癌症为目的疾病的实施例中,已知有抗肿瘤活性的5-氟脱氧尿嘧啶或其它核苷酸类似物可以分子内连接于腱生蛋白-C核酸配体内存在的U’s或分子内加入或直接或通过接头结合于其它末端。另外,可以结合嘧啶类似物2’2’-双氟胞嘧啶和嘌呤类似物(脱氧考福霉素)。再者,美国专利申请08/993,765,1997年11月8日申请,已完全附于参考文献中,描述了,尤其是,核苷酸类原药包括直接与肿瘤结合的核酸配体,例如腱生蛋白-C,用于精确定位的化学放射性感光剂,及放射性感光剂和放射性核素和其它抗肿瘤的放射性治疗剂。
同样受关注的是标记物与治疗剂都与腱生蛋白-C核酸配体结合,这样疾病状态的检测和输送治疗试剂可以在一个适体中一起完成或形成两个或多个同一适体的不同改良方式的混合物。还受关注的是标记物或治疗试剂或两者一起连接于非免疫原性的,高分子量复合物或亲脂性复合物,如脂质体。核酸配体与亲脂性复合物或非免疫原性复合物结合形成诊断或治疗复合物的方法在美国专利申请08/434,465,1995年5月4日申请,发明名称是“核酸配体复合物”中有描述,该专利申请已其全文引入本文作参考。
本文描述的治疗或诊断组分可以不经肠道注射施用(例如,静脉、皮下、皮内、损伤内注射),尽管其它有效的施用形式,诸如关节内注射、吸入薄雾、口服活性配方、皮肤电离子渗入或栓剂,也是可以预想的。还可以应用定点直接注射,可以从装置中释放出来,例如灌输支架或导管,或使用输液泵直接定点输送。一个优选的载体是生理盐水溶液,但预期其它药剂学承认的载体也可以使用。在一个实施例中,设想载体和腱生蛋白-C核酸配体与治疗复合物结合在一起形成适用于生理条件的缓释配方。这种载体的基本溶剂可以是天然的水溶液或非-水溶液。另外,载体可以含有其它药剂学接受的赋形剂进行修饰或保持配方的pH、克分子渗透压浓度、粘性、透明度、颜色、无菌性、稳定性、溶解速率,或气味。同样的,载体可以含有其它药剂学接受的赋形剂进行修饰或保持腱生蛋白-C核酸配体的稳定性、溶解速率、释放,或吸附。这种赋形剂是经常并通常用在按配方配制的,以单位剂量和多剂量形式,不经肠道施用的药物中的物质。
一旦治疗或诊断的组分配制好,应储存在无菌小瓶中,可以是溶液、悬浮液、胶状、乳剂、固体,或脱水或冻干的粉末。这种配药可以以使用形式储存或在施用前立即配置。含系统输送腱生蛋白-C核酸配体的配药的施用方式可以是通过皮下、肌肉内、静脉、关节内,鼻内或阴道内或直肠内栓剂。
下文提供的实施例用于解释和阐明本发明而本发明并不限制于此。实施例1描述了实施例2中使用的、用以产生腱生蛋白-C RNA配体的材料和试验程序。实施例2描述了腱生蛋白-C RNA配体及预测筛选的核酸配体的二级结构。实施例3描述了确定筛选核酸配体的高亲和力必须的最小大小,和嘌呤2’-OH替代为嘌呤2’-OMe。实施例4描述了荷瘤小鼠体内Tc-99m标记的腱生蛋白-C核酸配体的生物分布。实施例5描述了使用荧光标记的腱生蛋白-C核酸配体定位肿瘤组织中的腱生蛋白-C。实施例6描述了通过适体TTA1(即已知的GS7641)检测肿瘤。实施例7描述了使用111In进行另一种标记。
实施例
实施例1.应用SELEX获得腱生蛋白-C的核酸配体和U251胶质母细胞瘤细胞的核酸配体。
材料和方法
腱生蛋白-C购自Chemicon(Temecula,CA)。单链DNA引物和模板在Operon技术公司(Alameda,CA)合成。
SELEX程序在SELEX专利申请中有详细的描述。简言之,通过Klenow片段延伸40N7a ssDNA制备双链转录模板:
5’-TCGCGCGAGTCGTCTG[40N]CCGCATCGTCCTCCC 3’(SEQ IDNO:1)
使用5N7引物:
5’TAATACGACTCACTATAGGGAGGACGATGCGG-(SEQ IDNO:2),它含有T7聚合酶启动子(划线部分)。如Fitzwater和Polisky(1996)方法酶学267:275-301所述,用T7RNA聚合酶制备RNA,此文已其全文引入本文作参考。所有的转录反应均在糖分子有2’-氟(2’-F)修饰的嘧啶核苷酸存在下进行的。这个替代提供了更强的核糖核酸酶抗性,该酶在2’羟基处切割磷酸二酯键。尤其是,每个转录混合物含有3.3mM 2’-F UTP和3.3mM 2’-F CTP和1mM GTP及ATP。这样产生的初始随机RNA文库含3×1014个分子。用硝酸纤维素滤膜分离的标准方法测定腱生蛋白-C每个配体的亲和力(Tuerk和Gold(1990)科学249(4968):505-10)。
每一个SELEX循环,在Lumino平皿中加入200ul含腱生蛋白-C的Dulbecco氏PBS,浓度如表1所示,室温包被2小时。包被后,1-6个循环用HBSMC+缓冲液[20mM Hepes,pH7.4,137mMNaCl,1mM CaCl2,1mM MgCl2]和1g/升人血清白蛋白(Sigma,片段V)封闭小孔而第7和第8个循环用HBSMC+含1g/升酪蛋白的缓冲液封闭小孔。结合和漂洗缓冲液包括HBSMC+含0.05%Tween20的缓冲液。每一个SELEX循环,RNA稀释于100ul结合缓冲液中并在预先用结合缓冲液洗过的蛋白包被小孔中37℃孵育2小时。结合后,用200ul漂洗缓冲液分别洗6次。漂洗步骤之后,小孔放于95℃加热器中干燥5分钟。标准AMV逆转录酶反应(50ul)于48℃直接在小孔中进行,反应产物用于标准PCR和转录反应。两个合成引物5N7(见上)和3N7a:
5’-TCGCGCGAGTCGTCTG-3’(SEQ ID NO:3)
用于这些模板的扩增和逆转录步骤。
对细胞SELEX而言,U251人胶质母细胞瘤细胞(人类遗传(1971)21:238)在添加10%胎牛血清(GIBCO BRL.Gaithersburg.MD)的Dulbecco改良Eagle氏培养基和六孔组织培养皿(BectonDickinson Labware,Lincoln Park,NJ)中生长至汇合状态并用补充CaCl2的Dulbecco氏PBS缓冲液(DPBS,GIBCO BRL)洗三次。转录得到的分子内标记RNA(Fitzwater(1996)如上述)与细胞37℃孵育一小时。接着去除标记RNA,37℃用DPBS洗细胞六次,每次十分钟。然后加入含5mM EDTA的DPBS,并与细胞孵育30分钟洗脱漂洗步骤后仍结合于细胞上的RNA。用标准液闪计数程序计数RNA并用RT-PCR扩增。
U251细胞的结合分析。分子内标记的RNA在六孔组织培养皿(Becton I Dickinson Labware,Lincoln Park,NJ)中与浓度增高的汇合态U251细胞37℃孵育一小时。用DPBS+CaCl2,37℃洗三次,每次十分钟,洗去未结合的RNA,用Trizol(Gibco BRL,Gaithersburg,MD)破坏细胞收集结合的RNA。结合的RNA用液闪计数定量。
克隆和测序。用8%的聚丙烯酰胺凝胶分离扩增出的亲和力富集的寡核苷酸库,反转录成ssDNA并用含BamHI和HindIII限制性内切酶位点的引物通过聚合酶链式反应(PCR)扩增DNA。克隆PCR片段,根据标准技术(Sambrook等,(1989)分子克隆:实验室手册,第二版,3卷,冷泉港实验室出版社,冷泉港)进行质粒的制备和序列分析。
实施例2.腱生蛋白-C的RNA配体
通过SELEX程序获得U251细胞的核酸配体,在美国专利申请08/434,425,发明名称是“配体指数富集系统生成法:组织SELEX”,1995年5月3日申请,现是美国专利5,789,157,中有描述。接着确定获得的配体是腱生蛋白-C核酸配体。
为了获得人腱生蛋白-C的寡核酸配体,使用在上文材料和方法中描述的随机核苷酸文库进行了八个SELEX循环。每一循环中加入的RNA和蛋白如表1所示。8个SELEX循环后,寡核苷酸库对腱生蛋白-C的亲和力是10nM,而这种亲和力没有随着增加的SELEX循环增强。
为了获得U251胶质母细胞瘤细胞的配体,用随机核苷酸库进行了9个SELEX循环。经过9个循环的与U251细胞结合和EDTA洗脱后,测试了第3、5和9个循环与U251细胞结合的能力。图1显示SELEX循环数增加,RNA结合量的浓度也有显著增加。由于目的组织的复杂性,不可能估计寡核苷酸库对细胞表面未知分子的亲和力。
接着用E9库(九轮循环中结合于U251细胞又被EDTA洗脱的RNA配体)作为以纯化的腱生蛋白-C为靶的SELEX的起点。如上所述使用纯化腱生蛋白-C进行两个SELEX循环。两个SELEX(E9P1和E9P2)循环中加入的蛋白和RNA浓度如表2所述。总而言之,进行三种不同的SELEX试验:一个用纯化的腱生蛋白-C为靶,一个用U251胶质母细胞瘤作靶,另一个实验中纯化的腱生蛋白-C作靶,用来自U251胶质母细胞瘤的SELEX库启动SELEX试验。
通过克隆和测序分析三个SELEX试验,配体来自纯化腱生蛋白-C SELEX(“TN”序列)的第8轮循环,U251细胞SELEX(“E9”序列)的第9轮循环,和U251/腱生蛋白-C混合SELEX第2轮循环(“E9P2序列”)。表3中显示了34个特定克隆的序列,并分成两个大组:腱生蛋白-C配体(“TN”和“E9P2”序列)和U251细胞配体(“E9”)。腱生蛋白-C配体中,大多数克隆(共65个)代表命名为家族1和家族2的两个不同序列类型中的一个(图1)。检查家族1中12个克隆可变区揭示了与保守序列GACNYUUCCNGCYAC(SEQ ID NO:12)相近的7个特定序列。检查家族II中18个克隆的可变区揭示这些序列中均含有保守序列CGUCGCC(表3)。E9序列由于在可变区内有保守的GAY和CAU序列能够分入相近的一组。其余的序列似乎与其它序列没有关联被分为孤儿一类。三种主要的序列,E9P2-1、E9P2-2,和TN9各自代表14、16,和10倍。“孤儿”一类中,一个序列,TN18,代表两倍。总之,这些数据代表高度富集的序列库。
大部分个体的解离常数很低显示是十亿分之一,三种最普遍的序列亦是如此。TN9和E9P2-1和-2,具有最高的亲和力,分别是5nM,2nM,和8nM(表3)。这些结果显示U251细胞SELEX是腱生蛋白-C适体的储备,而且只需要两个SELEX循环分离细胞SELEX库中的腱生蛋白特异性配体。其它蛋白的寡核苷配体用纯化蛋白为靶同样可以从E9库中分离出来。
实施例3.确定TN9的最小大小,用2’-OMe嘌呤替代2’-OH:合成适体TTA1
寡核苷酸合成程序是本领域熟练技术人员使用的标准方法(Green等(1995)生物化学2(10):683-95)。2’-氟嘧啶phosphoramidite单体来自JBL Scientific(San Luis Obispo,CA);2’-OMe嘌呤,2’-OH嘌呤,己氨,和(CH2CH2O)6单体,及dT聚苯乙烯固相支持物,来自Glen Research(Sterling,VA)。适体亲和力用硝酸纤维素滤膜分离(Green等,如上述)确定。
根据TN9对腱生蛋白-C的高亲和力,选择它做进一步分析。我们首先研究了高亲和力结合所需的最小序列。使用标准技术(Green等,如上述),发现核苷酸55的3’核苷是结合腱生蛋白-C所需要的,然而去除5’末端的任何核酸都会造成亲和力的损失。进一步从55位核苷酸缩短TN9的长度并保留高亲和力结合活性,接着我们尝试界定了TN9分子内的缺失。将TN9的前55个核苷酸,与相近的家族II配体TN7,TN21,和TN41的前55个核苷酸输入计算机运算以确定可能的RNA二级结构折叠(mfold 3.0,可在http://www.ibc.wustl.edu/-zuker/网址下载M.Zuker,D.H.Mathews&D.H.Turner RNA二级结构预测的运算法则和热力学:应用指南。在:RNA生物化学和生物技术,J.Barciszewski&B.F.C.Clark,著,NATO ASI系列,Kluwer学院出版社,(1999))。运算法则推测出的许多可能的RNA折叠中,发现了每一个核苷酸都有的结构。图2的寡核苷酸代表的这个结构,含有三个茎部结构并在一个交叉点汇合,所以称为3-茎交叉。这个折叠使家族II寡核苷酸中的高度保守核苷酸处于交叉区。比较TN9、TN7、TN21,和TN41,第二个茎部结构的长度和序列是可变的,说明腱生蛋白-C的结合不需要第二个茎部的延伸。应用TN9测试这个假设,我们发现核苷酸10-26可以被乙烯乙二醇接头,((CH2CH2O)6替代。接头是环状替代物,减小了适体大小。另外,替代10-26位核苷酸的四-核苷酸环(CACU或GAGA)产生对腱生蛋白-C高亲和力的序列。确定其它核苷酸环或其它间隔子能够替代10-26位核苷酸形成腱生蛋白-C高亲和力序列的技术完全属于本领域的熟练技术。
为了增强抗核酸酶的活性,嘌呤位置可以定点替换成相应的2’-OMe。寡核苷酸可任意分为五部分而每一部分中的所有嘌呤都替换成相应的2’-OMe嘌呤核苷酸,总共五个寡核苷酸(表4,相I合成)。确定每个寡核苷酸的腱生蛋白-C的亲和力,发现1、3和5部分的所有嘌呤可以在不损失亲和力的情况下被替换。2和4部分中,逐个将嘌呤替换成2’-OMe嘌呤并检测有效的亲和力(表4,相III合成)。从这些实验中,推测将G9、G28、G31、和G34替换成2’-OMeG造成腱生蛋白-C亲和力的损失。因此在适体TTA1中保留这些核苷酸的2’-OH。
然后将适体TTA1(表4)与(CH2CH2O)6接头(间隔子18)、核酸外切酶保护的3’-3’dT帽、5’己氨(表4),和除表4中显示的5Gs外的所有2’-OH嘌呤一起合成。一种不能结合的对照适体,TTA1.NB,通常是通过删去3’末端的5个核苷酸产生的。TTA1结合腱生蛋白-C的平衡解离常数(Kd)是5nM,而TTA1.NB结合腱生蛋白-C的Kd>5uM。
核苷酸10-26能替换成非核苷酸的乙烯乙二醇接头。因此可以将两个部分独立合成,断开处引入乙烯乙二醇接头并产生新的5’和3’末端。合成后,共同孵育两个分子形成杂合体。本方法可以在新的5’和3’末端引入其它氨基基团和核苷酸。新功能可以用于生物连接。另外,由于两部分合成缩短了分子的长度,增强了化学合成的产量。实施例4荷瘤小鼠中Tc-99m标记适体的生物分布
如图2所示将Tc-99m螯合剂(Hi15:Hilger等(1998)TetLett39:9403-9406)结合于寡核苷酸的5’末端检测适体的生物分布。Tc-99m标记的适体形式示于图10中。TTA1和TTA1.NB与50mg/ml的适体结合,该适体存在于含5摩尔当量Hi15-N-hydoxysuccinimide的30%二甲基甲酰胺中,并用pH 9.0的100mM硼酸钠在室温平衡30分钟。Tc-99m标记形式的适体如图10所示。反相HPLC纯化产生Hi15-TTA1和Hi15-TTA1.NB。接着以下列方式用Tc-99m标记寡核苷酸:1nmole Hi15-适体中加入200uL 100mM磷酸钠缓冲液,pH8.5,23mg/mL酒石酸钠,和从Mo 99柱子(Symcor,Denver)洗脱的,需在12小时内使用的Tc-99m高锝酸盐(5.0mCi)50uL。标记反应需另加10uL 5mg/mL SnCl2启动。反应混合物90℃孵育15分钟。通过截流分子量是30,000的膜(Centrex,Schleicher&Scheull)进行旋转透析,用300uL洗两次,将反应混合物与未反应的Tc-99m分离。这个标记过程使得30-50%加入的99m Tc以2-3mCi/nmoleRNA的特定活性结合于寡核苷酸。
生物分布实验中,U251肿瘤移植物按如下方法制备:U251细胞培养于的Dulbecco改良Eagle氏培养基中,其中添加了体积比是10%的胎牛血清。给去除胸腺的小鼠皮下注射1X106 U251细胞。当肿瘤大小达到200-300mg(1-2周)时,3.25mg/kg静脉注射Tc-99m
标记的适体。在指示的时间,用异氟醚麻醉小鼠(Fort DodgeAnimal Health,Fort Dodge,IA),通过心脏穿刺收集血液,处死动物并收获组织。Tc-99m水平用伽玛计数计算(Wallac Oy,Turku,Finland)。用每克组织注射剂量百分数计算组织摄取的适体(%ID/g)。
用伽玛摄像机获取小鼠影像。将麻醉(异氟醚)的小鼠放置于摄像机(西门子,LEM+)上。收集数据(30秒-10分钟)并在Power MACG3(苹果计算机,CA)上用版本3.22.2的核MAC软件(科学显影,CA)分析。
生物分布实验,如表5,说明适体在肿瘤组织中的快速和特异摄取;肿瘤中没有残留的未结合的适体。血液中的Tc-99m同样被快速的清除掉了。三小时后,使用Hi15-TTA1带入肿瘤中的Tc-99m水平半衰期很长()18小时)。这说明一旦适体穿透进入肿瘤,偶联的标记物在肿瘤中保持较长时间。此数据显示与适体偶联的细胞毒性试剂,包括放射性核物质和非放射性试剂可以在肿瘤中以较长的半衰期存在。
Tc-99m的放射性也在其它组织中出现,值得注意的是小肠和大肠。本领域熟练技术人员可以简易的改变本文所用的肝胆管清除模式,例如改变Tc-99m螯合剂的亲水性、改变螯合剂、或同时改变放射性金属/螯合剂的配对。
整个动物显影在注射Tc-99m标记的Hi15-TTA13小时后可以获取。注射Hi15-TTA1的小鼠的显影,而不是注射Hi15-TTA1.NB的小鼠的显影,清楚的显示了肿瘤(图3)。正如生物分布实验预测的,胃肠道中的放射性很明显。
实施例5.使用荧光标记的TTA1定位肿瘤组织中的腱生蛋白-C
材料和方法
TTA1和TTA1.NB如上合成。Succinimdyl若丹明-Red-X(分子探针,Eugene,OR)如上述连接于适体的5’氨基形成H15-NHS偶联。用反相HPLC纯化若丹明-Red-X-偶联的适体,TTA1-Red和TTA1.NB-Red。U251细胞的培养和肿瘤在裸鼠中的生长如上文所述。5nmol TTA1-Red或TTA1.NB-Red静脉注射于裸鼠中并在预期时间麻醉动物,灌注0.9%NaCl,再处死。切除肿瘤放置于福尔马林中。24小时浸泡后,切下10uM部分并用荧光显微镜检测若丹明-Red-X(Eclipse E800,尼康,日本)。
结论:TTA1-Red与5nM未结合的原始适体,TTA1有相同的腱生蛋白-C亲和力。我们比较注射TTA1-Red和TTA1.NB-Red 10分钟后的肿瘤荧光水平。结合的适体,TTA1-Red,使肿瘤而不是邻近组织有强烈的荧光着色(图4)。这些结果说明应用适体进行体内腱生蛋白-C荧光检测,相同的适体可以用于回体组织染色。
实施例6.用适体TTA1(现已知为GS7641)进行肿瘤的体内检测:其它肿瘤类型。
适体标记、生物分布,和裸鼠肿瘤移植物的操作如实施例4所述。
已知许多人类肿瘤表达腱生蛋白-C。为了评定TTA1/GS7641进入除胶质母细胞瘤之外的其它肿瘤的能力,在裸鼠中种植人肿瘤细胞形成肿瘤。检测肿瘤组织人腱生蛋白-C的表达,并检测表达腱生蛋白-C的肿瘤对适体的摄取。图6显示适体在几种肿瘤中的摄取情况,包括胶质母细胞瘤、乳腺癌、结肠癌,和横纹肌肉瘤。通过比较结合(TTA1/GS7641)和不能结合的适体(TTA1.NB)说明肿瘤的特异性摄取。要注明的是KB,表达小鼠而不是人腱生蛋白-C的移植物,并没有摄取。本实验将胶质母细胞瘤的摄取实验结果扩展到其它肿瘤和肉瘤,并进一步说明所有表达人腱生蛋白-C的肿瘤均显示有TTA1/GS7641的摄取。
实施例7.选用In-111进行标记
实施例4中描述了肿瘤异种移植和生物分布研究。DTPA和DOTA中的环酐与TTA1/GS7641上的氨基在中性pH条件下用标准方法孵育,把DTPA和DOTA耦联于TTA1/GS7641。DTPA和结合物的结构分别见图8和图9所示,其中每一种都用In-111标记。DOTA结合物与DTPA结合物的接头相同。DOTA-和DTPA-复合物与In-111在95℃,pH5.5,0.5M的NaOAc中孵育30分钟,进行标记。用30K截留膜旋转透析去除未结合的放射性标记物,标记好的适体溶于磷酸盐缓冲液,注射荷瘤小鼠。
In-111标记适体与实施例4中描述的Tc标记适体相比,其生物分布显著不同。图7显示In-111标记的TTA1/GS7641与Tc-99m标记的TTA1/GS7641相比,其放射活性在小肠中大大减少,在肝脏和肾脏中的吸收共同增加。这个实验表明在动物体内螯合物的化学特性对TTA1/GS7641放射标记物的分布有很大影响。与Hi15-TTA1/GS7641的生物分布方式不同,在某些不需要肝胆清除的临床情况下,可能用于肿瘤的打靶。这些情况包括但不只限于放疗和小肠、前列腺和其它腹区的成像。
表1.腱生蛋白-C SELEX RNA和蛋白投入
| 腱生蛋白-C | RNA | |
| 循环 | (皮摩尔/孔) | (皮摩尔/孔) |
| 1 | 12 | 200 |
| 2 | 12 | 200 |
| 3 | 12 | 200 |
| 4 | 12 | 200 |
| 5 | 2 | 33 |
| 6 | 2 | 33 |
| 7 | 2 | 33 |
| 8 | 0.2 | 3.3 |
表2.细胞SELEX/腱生蛋白-C SELEX RNA和蛋白投入
| 腱生蛋白-C | RNA | |
| 循环 | (皮摩尔/孔) | (皮摩尔/孔) |
| E9P1 | 2 | 33 |
| E9P2 | 2 | 33 |




序列表
<110>吉利德科学公司
<120>腱生蛋白-C核酸配体
<130>NEX 86/PCT
<140>
<141>
<150>09/364,902
<151>1999-07-29
<160>65
<170>PatentIn Ver.2.0
<210>1
<211>71
<212>DNA
<213>人工序列
<220>
<221>修饰碱基
<222>(1)..(56)
<223>在17-56位的N是A,C,T,或G
<400>1
tcgcgcgagt cgtctgnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnccgc 60
atcgtcctcc c 71
<210>2
<211>32
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<400>2
taatacgact cactataggg aggacgatgc gg 32
<210>3
<211>16
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<400>3
tcgcgcgagt cgtctg 16
<210>4
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>4
gggaggacga ugcggcaauc aaaacucacg uuauucccuc aucuauuagc uuccccagac 60
gacucgcccg a 71
<210>5
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>5
gggaggacga ugcggcaauc uccgaaaaag acucuuccug cauccucuca ccccccagac 60
gacucgcccg a 71
<210>6
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>6
gggaggacga ugcggcaacc ucgaaagacu uuucccgcau cacuguguac ucccccagac 60
gacucgcccg a 71
<210>7
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>7
gggaggacga ugcggcaacc ucgauagacu uuucccgcau cacuguguac ucccccagac 60
gacucgcccg a 71
<210>8
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>8
gggaggacga ugcggcaacc ucaaucuuga cauuucccgc accuaaauuu gcccccagac 60
gacucgcccg a 71
<210>9
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>9
gggaggacga ugcggcaaac gaucacuuac cuuuccugca ucugcuagcc ucccccagac 60
gacucgcccg a 71
<210>10
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>10
gggaggacga ugcggacgcc agccauugac ccucgcuucc acuauuccau ccccccagac 60
gacucgcccg a 71
<210>11
<211>70
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(70)
<223>所有嘧啶均是2′F
<400>11
gggaggacga ugcggccaac cucauuuuga cacuucgccg caccuaauug cccccagacg 60
acucgcccga 70
<210>12
<211>15
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(15)
<223>所有嘧啶均是2′F
<220>
<221>修饰碱基
<222>(1)..(15)
<223>在4和10位的N是A,G,2′-F-U或2′-F-C
<400>12
gacnyuuccn gcayc 15
<210>13
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>13
gggaggacga ugcggaaccc auaacgcgaa ccgaccaaca ugccucccgu gcccccagac 60
gacucgcccg a 71
<210>14
<211>70
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(70)
<223>所有嘧啶均是2′F
<400>14
gggaggacga ugcggugccc auagaagcgu gccgcuaaug cuaacgcccu cccccagacg 60
acucgcccga 70
<210>15
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>15
gggaggacga ugcggugccc acuaugcgug ccgaaaaaca uuucccccuc uaccccagac 60
gacucgcccg a 71
<210>6
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>16
gggaggacga ugcggaacac uuucccaugc gucgccauac cggauauauu gcucccagac 60
gacucgcccg a 71
<210>17
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>17
gggaggacga ugcggacugg accaaaccgu cgccgauacc cggauacuuu gcucccagac 60
gacucgcccg a 71
<210>18
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>18
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccugcagac 60
gacucgcccg a 71
<210>19
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>19
gggaggacga ugcgguuaag ucucgguuga augcccaucc cagauccccc ugacccagac 60
gacucgcccg a 71
<210>20
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>20
gggaggacga ugcggauggc aagucgaacc aucccccacg cuucuccugu ucccccagac 60
gacucgcccg a 71
<210>21
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>21
gggaggacga ugcgggaagu uuucucugcc uugguuucga uuggcgccuc ccccccagac 60
gacucgcccg a 71
<210>22
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>22
gggaggacga ugcggucgag cggucgaccg ucaacaagaa uaaagcgugu cccugcagac 60
gacucgcccg a 71
<210>23
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>23
gggaggacga ugcggauggc aagucgaacc aucccccacg cuucuccugu ucccccagac 60
gacucgcccg a 71
<210>24
<211>76
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(76)
<223>所有嘧啶均是2′F
<400>24
gggaggacga ugcggacuag accgcgaguc cauucaacuu gcccaaaaaa aaaccucccc 60
cagacgacuc gcccga 76
<210>25
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>25
gggaggacga ugcgggagau caacauuccu cuaguuuggu uccaaccuac acccccagac 60
gacucgcccg a 71
<210>26
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>26
gggaggacga ugcggacgag cgucucauga ucacacuauu ucgucucagu gugcacagac 60
gacucgcccg a 71
<210>27
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>27
gggaggacga ugcggucgac cucgaaugac ucuccaccua ucuaacaucc ccccccagac 60
gacucgcccg a 71
<210>28
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>28
gggaggacga ugcggucgac cucgaaugac ucuccaccua ucuaacagcc uuccccagac 60
gacucgcccg a 71
<210>29
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>29
gggaggacga ugcggagaac ucauccuaac cgcucuaaca aaucuugucc gaccgcagac 60
gacucgcccg a 71
<210>30
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>30
gggaggacga ugcggauaau ucgacaccaa ccaggucccg gaaaucaucc cucugcagac 60
gacucgcccg a 71
<210>31
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>31
gggaggacga ugcggaaacc aaccguugac caccuuuucg uuuccggaaa guccccagac 60
gacucgcccg a 71
<210>32
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>32
gggaggacga ugcggaagcc aacccucuag ucagccuuuc guuucccacg ccacccagac 60
gacucgcccg a 71
<210>33
<211>72
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(72)
<223>所有嘧啶均是2′F
<400>33
gggaggacga ugcgggacca acuaaacugu ucgaaagcug gaacaugucc ugacgccaga 60
cgacucgccc ga 72
<210>34
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>34
gggaggacga ugcggaccaa cuaaacuguu cgaaagcugg aacacguccu gacgccagac 60
gacucgcccg a 71
<210>35
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>35
gggaggacga ugcggaccaa cuaaacuguu cgaaagcuag aacacgucca gacgccagac 60
gacucgcccg a 71
<210>36
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>36
gggaggacga ugcggaccaa cuaaacuguu cgaaagcugg aacacguucu gacgccagac 60
gacucgcccg a 71
<210>37
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>37
gggaggacga ugcggaccaa cuaaacuguu cgaaagcugg aauacguccu gacgccagac 60
gacucgcccg a 71
<210>38
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>38
gggaggacga ugcggaaguu uagugcucca guuccgacac uccucuacuc agccccagac 60
gacucgcccg a 71
<210>39
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>39
gggaggacga ugcggagcca gagccucucu caguucuaca gaacuuaccc acuggcagac 60
gacucgcccg a 71
<210>40
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>40
gggaggacga ugcggaccua acucaaucag gaaccaaacc uagcacucuc auggccagac 60
gacucgcccg a 71
<210>41
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>41
gggaggacga ugcgggagau caacauuccu cuaguuuggu uccaaccuac acccccagac 60
gacucgcccg a 71
<210>42
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>42
gggaggacga ugcggaucuc gauccuucag cacuucauuu cauuccuuuc ugccccagac 60
gacucgcccg a 71
<210>43
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>43
gggaggacga ugcggacgau ccuuuccuua acauuucauc auuucucuug ugccccagac 60
gacucgcccg a 71
<210>44
<211>71
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(71)
<223>所有嘧啶均是2′F
<400>44
gggaggacga ugcggugacg acaacucgac ugcauaucuc acaacuccug ugccccagac 60
gacucgcccg a 71
<210>45
<211>72
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(72)
<223>所有嘧啶均是2′F
<400>45
gggaggacga ugcggacuag accgcgaguc cauucaacuu gcccaaaaac cucccccaga 60
cgacucgccc ga 72
<210>46
<211>70
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(70)
<223>所有嘧啶均是2′F
<400>46
gggaggacga ugcgggcgca ucgagcaaca uccgauucgg auuccuccac ucccccagac 60
gacugcccga 70
<210>47
<211>50
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(50)
<223>所有嘧啶均是2′F;50和51位的键是3′-3′.
<400>47
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu 50
<210>48
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;55和56位的键是3′-3′.
<400>48
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>49
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5和55的g是2′OMe;
位置4的a是2′OMe;55和56位的键是3′-3′.
<400>49
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>50
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置6,9,12和14的g是2′OMe;
位置7和10的a是2′OMe;位的键是3′-3′.
<400>50
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>51
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置15和22的g是2′OMe;
位置16-17,19-20和24的a是2′OMe;55和56位的键是3′-3′.
<400>51
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>52
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置38,41和44的g是2′OMe;
55和56位的键是3′-3′.
<400>52
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>53
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置39-40,43和48的g是2′OMe;
位置36-37和41的a是2′OMe;55和56位的键是3′-3′.
<400>53
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>54
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5-6,9,12,14-15,22,28,31,34,39-40,43,48和55的g是2′OMe.
<220>
<221>修饰碱基
<222>(1)..(55)
<223>位置7,10,16-17,19-20,24,36-37,和41的a是2′OMe;
55和56位的键是3′-3′.
<400>54
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>55
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5-6,9,12,14-15,22,39-40,43,48和55的g是2′OMe ;位置4,7,10,16-17,19-20,24-36-37,40的a是2′OMe.
<220>
<221>修饰碱基
<222>(1)..(55)
<223>55和56位的键是3′-3′.
<400>55
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>56
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5-6,15,22,39-40,43,48和55的g是2′OMe;位置4,16-17,19-20,2436-37和40的a是2′OMe;55和56位的键是3′-3′.
<400>56
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>57
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5,15,22,39-40,43,48,55的g是2′OMe;位置4,7,16-17,19-20,24,36-37,40的a是2′OMe;55,56位的键是3′-3′.
<400>57
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>58
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5,9,15,22,39-40,43,48,55的g是2′OMe;位置4,16-17,19-20,24,36-37,41的a是2′OMe;55,56位的键是3′-3′.
<400>58
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>59
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5,15,22,39-40,43,48和55的g是2′OMe;位置4,10,16-17,19-20,24,36-37,和41的a是2′OMe;55和56位的键是3′-3′.
<400>59
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>60
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5,12,14-15,22,39-40,43,48和55的g是2′OMe;位置4,16-17,19-20,24,36-37和41的a是2′OMe;55和56位的键是3′-3′.
<400>60
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>61
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,6,15,22,28,39-40,43,48,和55的g是2′OMe;位置4,16-17,19-20,24,36-37和40的a是2′OMe;55和56位的键是3′-3′.
<400>61
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>62
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5,15,22,39-40,43,48和55的g是2′OMe;位置4,16-17,19-20,27,36-37和40的a是2′OMe;55和56位的键是3′-3′.
<400>62
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>63
<211>55
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(55)
<223>所有嘧啶均是2′F;位置1-3,5,15,22,39-40,43,48和55的g是2′OMe;位置4,16-17,19-20,24,36-37,和40的a是2′OMe;55和56位的键是3′-3′.
<400>63
gggaggacga ugcggaacaa ugcacucguc gccguaaugg auguuuugcu cccug 55
<210>64
<211>39
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(39)
<223>所有嘧啶均是2′F;位置2-3,5-6,23-24,27,32,和39的g是2′OMe ;位置4,7,20-21,和25的a是2′OMe;.
<220>
<221>修饰碱基
<222>(1)..(39)
<223>39和40位的键是3′-3′.
<220>
<221>修饰碱基
<222>(1)..(39)
<223>在10位的N是(CH2CH2O)6
<400>64
gggaggacgn cgucgccgua auggauguuu ugcucccug 39
<210>65
<211>34
<212>RNA
<213>人工序列
<220>
<223>人工序列的描述:核酸
<220>
<221>修饰碱基
<222>(1)..(34)
<223>所有嘧啶均是2′F;位置2-3,5-6,23-24,27和32的g是2′OMe;位置4,7,20-21,和25的a是2′OMe
<220>
<221>修饰碱基
<222>(1)..(34)
<223>在10位的N是(CH2CH2O)6
<220>
<221>修饰碱基
<222>(1)..(34)
<223>34和35位的键是3′-3′
<400>65
gggaggacgn cgucgccgua auggauguuu ugcu 34
Claims (9)
1、用于体内诊断的复合物,包含选自如下一组的化合物:

其中L是选自SEQ ID NO:4-65的一种腱生蛋白-C核酸配体。
2、权利要求1的复合物,其中L是:
G667667CG-(CH2CH2O)6-CGUCGCCGU77U667U6UUUU6CUCCCU65
且其中:
所有的嘧啶是2′F;
6=2′OMe G;
7=2′OMe A;且
5=3′-3′dT。
3、权利要求1的复合物,其中所述接头是具有式(-NH(CH2)6OPO3 -)的己胺接头。
4、一种标记物-核酸复合物在生产用于在可能患有表达腱生蛋白-C的疾病的生物组织中检测此疾病存在的诊断剂中的用途,检测步骤包括:
a)将可能患有所述疾病的组织暴露于所述的复合物;并
b)在所述的组织中检测所述复合物的存在,
其中所述的标记物-核酸复合物选自如下一组:
其中L是选自SEQ ID NO:4-65的一种腱生蛋白-C核酸配体。
5、权利要求4的用途,其中L是:
G667667CG-(CH2CH2O)6-CGUCGCCGU77U667U6UUUU6CUCCCU65
且其中:
所有的嘧啶是2′F;
6=2′OMe G;
7=2′OMe A;且
5=3′-3′dT。
6、权利要求5的用途,进一步包含将一种治疗剂或诊断剂与所述的复合物相附着。
7、权利要求5的用途,其中所述的疾病选自癌症、牛皮癣和动脉粥样硬化。
8、权利要求7的用途,其中所述的疾病是癌症。
9、权利要求4的用途,其中所述接头是具有式(-NH(CH2)6OPO3 -)的己胺接头。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/364,902 US6232071B1 (en) | 1990-06-11 | 1999-07-29 | Tenascin-C nucleic acid ligands |
| US09/364,902 | 1999-07-29 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB008109796A Division CN1164760C (zh) | 1999-07-29 | 2000-01-28 | 腱生蛋白-c核酸配体 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1589908A CN1589908A (zh) | 2005-03-09 |
| CN100558411C true CN100558411C (zh) | 2009-11-11 |
Family
ID=23436596
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB008109796A Expired - Fee Related CN1164760C (zh) | 1999-07-29 | 2000-01-28 | 腱生蛋白-c核酸配体 |
| CNB2004100629077A Expired - Fee Related CN100558411C (zh) | 1999-07-29 | 2000-01-28 | 腱生蛋白-c核酸配体 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB008109796A Expired - Fee Related CN1164760C (zh) | 1999-07-29 | 2000-01-28 | 腱生蛋白-c核酸配体 |
Country Status (29)
| Country | Link |
|---|---|
| US (4) | US6232071B1 (zh) |
| EP (1) | EP1198589B9 (zh) |
| JP (1) | JP2003505111A (zh) |
| KR (1) | KR100605072B1 (zh) |
| CN (2) | CN1164760C (zh) |
| AT (1) | ATE405675T1 (zh) |
| AU (1) | AU767501C (zh) |
| BG (1) | BG106361A (zh) |
| BR (1) | BR0013170A (zh) |
| CA (1) | CA2380473A1 (zh) |
| CZ (1) | CZ2002365A3 (zh) |
| DE (1) | DE60039986D1 (zh) |
| DK (1) | DK1198589T3 (zh) |
| EA (1) | EA004795B1 (zh) |
| EE (1) | EE200200051A (zh) |
| ES (1) | ES2310989T3 (zh) |
| HK (1) | HK1048499B (zh) |
| HR (1) | HRP20020186A2 (zh) |
| HU (1) | HUP0202221A3 (zh) |
| IL (2) | IL147872A0 (zh) |
| MX (1) | MXPA02000819A (zh) |
| NO (1) | NO20020424L (zh) |
| NZ (2) | NZ516907A (zh) |
| PL (1) | PL201637B1 (zh) |
| RS (1) | RS50426B (zh) |
| SK (1) | SK1222002A3 (zh) |
| UA (1) | UA75578C2 (zh) |
| WO (1) | WO2001009390A1 (zh) |
| ZA (1) | ZA200200747B (zh) |
Families Citing this family (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6232071B1 (en) * | 1990-06-11 | 2001-05-15 | Gilead Sciences, Inc. | Tenascin-C nucleic acid ligands |
| US7005260B1 (en) * | 2000-01-28 | 2006-02-28 | Gilead Sciences, Inc. | Tenascin-C nucleic acid ligands |
| US7645743B2 (en) * | 1999-12-22 | 2010-01-12 | Altermune, Llc | Chemically programmable immunity |
| CA2328356A1 (en) | 1999-12-22 | 2001-06-22 | Itty Atcravi | Recreational vehicles |
| ES2474192T3 (es) | 2001-05-25 | 2014-07-08 | Duke University | Moduladores de agentes farmacol�gicos |
| US20040249130A1 (en) * | 2002-06-18 | 2004-12-09 | Martin Stanton | Aptamer-toxin molecules and methods for using same |
| EP1552002A4 (en) * | 2002-06-18 | 2006-02-08 | Archemix Corp | APTAMER TOXIN MOLECULES AND METHOD FOR THEIR USE |
| US8853376B2 (en) | 2002-11-21 | 2014-10-07 | Archemix Llc | Stabilized aptamers to platelet derived growth factor and their use as oncology therapeutics |
| US8039443B2 (en) * | 2002-11-21 | 2011-10-18 | Archemix Corporation | Stabilized aptamers to platelet derived growth factor and their use as oncology therapeutics |
| US10100316B2 (en) | 2002-11-21 | 2018-10-16 | Archemix Llc | Aptamers comprising CPG motifs |
| US7727969B2 (en) * | 2003-06-06 | 2010-06-01 | Massachusetts Institute Of Technology | Controlled release nanoparticle having bound oligonucleotide for targeted delivery |
| US20080268478A1 (en) * | 2005-03-01 | 2008-10-30 | Cedars-Sinai Medical Center | Use of Eotaxin as a Diagnostic Indicator For Atherosclerosis and Vascular Inflammation |
| AR052741A1 (es) * | 2005-04-08 | 2007-03-28 | Noxxon Pharma Ag | Acidos nucleicos de union a ghrelin |
| EP1897562A1 (en) * | 2006-09-08 | 2008-03-12 | Bayer Schering Pharma Aktiengesellschaft | Aptamers labelled with Gallium-68 |
| EP2063918B1 (en) | 2006-09-08 | 2014-02-26 | Piramal Imaging SA | Compounds and methods for 18f labeled agents |
| US20110136099A1 (en) | 2007-01-16 | 2011-06-09 | Somalogic, Inc. | Multiplexed Analyses of Test Samples |
| US8975026B2 (en) | 2007-01-16 | 2015-03-10 | Somalogic, Inc. | Method for generating aptamers with improved off-rates |
| CA3022666C (en) * | 2007-07-17 | 2022-04-19 | Somalogic, Inc. | Multiplexed analyses of test samples |
| EP2036981A1 (en) * | 2007-09-12 | 2009-03-18 | Bayer Schering Pharma Aktiengesellschaft | Aptamers labeled with 18F |
| US8604184B2 (en) | 2009-05-05 | 2013-12-10 | The United States Of America As Represented By The Secretary Of The Air Force | Chemically programmable immunity |
| US8236570B2 (en) | 2009-11-03 | 2012-08-07 | Infoscitex | Methods for identifying nucleic acid ligands |
| US8841429B2 (en) | 2009-11-03 | 2014-09-23 | Vivonics, Inc. | Nucleic acid ligands against infectious prions |
| GB201114662D0 (en) | 2011-08-24 | 2011-10-12 | Altermune Technologies Llc | Chemically programmable immunity |
| CN102533772B (zh) * | 2011-12-12 | 2013-10-09 | 中国科学院武汉病毒研究所 | 一种抗hbv诱饵适体及其筛选方法 |
| KR20140109956A (ko) * | 2011-12-12 | 2014-09-16 | 아이시스 이노베이션 리미티드 | 테나신-c 및 류마티스 관절염에서의 이의 용도 |
| US9982257B2 (en) | 2012-07-13 | 2018-05-29 | Wave Life Sciences Ltd. | Chiral control |
| CN107058596A (zh) * | 2017-06-19 | 2017-08-18 | 上海市第十人民医院 | 一种与恶性胶质瘤诊断相关的标志物及其应用 |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE3588239T3 (de) | 1985-03-30 | 2007-03-08 | Kauffman, Stuart A., Santa Fe | Verfahren zum Erhalten von DNS, RNS, Peptiden, Polypeptiden oder Proteinen durch DMS-Rekombinant-Verfahren |
| WO1989006694A1 (en) | 1988-01-15 | 1989-07-27 | Trustees Of The University Of Pennsylvania | Process for selection of proteinaceous substances which mimic growth-inducing molecules |
| ES2259800T3 (es) * | 1990-06-11 | 2006-10-16 | Gilead Sciences, Inc. | Procedimientos de uso de ligandos de acido nucleico. |
| US6610841B1 (en) * | 1997-12-18 | 2003-08-26 | Gilead Sciences, Inc. | Nucleotide-based prodrugs |
| US5496938A (en) * | 1990-06-11 | 1996-03-05 | Nexstar Pharmaceuticals, Inc. | Nucleic acid ligands to HIV-RT and HIV-1 rev |
| US6232071B1 (en) * | 1990-06-11 | 2001-05-15 | Gilead Sciences, Inc. | Tenascin-C nucleic acid ligands |
| US6127119A (en) * | 1990-06-11 | 2000-10-03 | Nexstar Pharmaceuticals, Inc. | Nucleic acid ligands of tissue target |
| US5789157A (en) * | 1990-06-11 | 1998-08-04 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| WO1992014843A1 (en) | 1991-02-21 | 1992-09-03 | Gilead Sciences, Inc. | Aptamer specific for biomolecules and method of making |
| US5683874A (en) * | 1991-03-27 | 1997-11-04 | Research Corporation Technologies, Inc. | Single-stranded circular oligonucleotides capable of forming a triplex with a target sequence |
| US5582981A (en) * | 1991-08-14 | 1996-12-10 | Gilead Sciences, Inc. | Method for identifying an oligonucleotide aptamer specific for a target |
| US5436132A (en) * | 1993-02-13 | 1995-07-25 | Amano Pharmaceutical Co., Ltd. | Quantitative determination of tenascin as glioma marker |
| US5859228A (en) * | 1995-05-04 | 1999-01-12 | Nexstar Pharmaceuticals, Inc. | Vascular endothelial growth factor (VEGF) nucleic acid ligand complexes |
| US6229002B1 (en) * | 1995-06-07 | 2001-05-08 | Nexstar Pharmaceuticlas, Inc. | Platelet derived growth factor (PDGF) nucleic acid ligand complexes |
| IL129497A0 (en) * | 1996-10-25 | 2000-02-29 | Nexstar Pharmaceuticals Inc | Vascular endothelial growth factor (vegf) nucleic acid ligand complexes |
| US6242246B1 (en) * | 1997-12-15 | 2001-06-05 | Somalogic, Inc. | Nucleic acid ligand diagnostic Biochip |
-
1999
- 1999-07-29 US US09/364,902 patent/US6232071B1/en not_active Expired - Fee Related
-
2000
- 2000-01-28 BR BR0013170-9A patent/BR0013170A/pt not_active Application Discontinuation
- 2000-01-28 CA CA002380473A patent/CA2380473A1/en not_active Abandoned
- 2000-01-28 WO PCT/US2000/002167 patent/WO2001009390A1/en active IP Right Grant
- 2000-01-28 MX MXPA02000819A patent/MXPA02000819A/es not_active IP Right Cessation
- 2000-01-28 KR KR1020027001167A patent/KR100605072B1/ko not_active IP Right Cessation
- 2000-01-28 UA UA2002021549A patent/UA75578C2/uk unknown
- 2000-01-28 PL PL353357A patent/PL201637B1/pl not_active IP Right Cessation
- 2000-01-28 NZ NZ516907A patent/NZ516907A/en unknown
- 2000-01-28 AU AU33519/00A patent/AU767501C/en not_active Ceased
- 2000-01-28 DE DE60039986T patent/DE60039986D1/de not_active Expired - Lifetime
- 2000-01-28 RS YUP-64/02A patent/RS50426B/sr unknown
- 2000-01-28 CZ CZ2002365A patent/CZ2002365A3/cs unknown
- 2000-01-28 IL IL14787200A patent/IL147872A0/xx active IP Right Grant
- 2000-01-28 AT AT00911657T patent/ATE405675T1/de not_active IP Right Cessation
- 2000-01-28 DK DK00911657T patent/DK1198589T3/da active
- 2000-01-28 EP EP00911657A patent/EP1198589B9/en not_active Expired - Lifetime
- 2000-01-28 CN CNB008109796A patent/CN1164760C/zh not_active Expired - Fee Related
- 2000-01-28 JP JP2001513645A patent/JP2003505111A/ja active Pending
- 2000-01-28 CN CNB2004100629077A patent/CN100558411C/zh not_active Expired - Fee Related
- 2000-01-28 EE EEP200200051A patent/EE200200051A/xx unknown
- 2000-01-28 SK SK122-2002A patent/SK1222002A3/sk not_active Application Discontinuation
- 2000-01-28 EA EA200200094A patent/EA004795B1/ru not_active IP Right Cessation
- 2000-01-28 ES ES00911657T patent/ES2310989T3/es not_active Expired - Lifetime
- 2000-01-28 HU HU0202221A patent/HUP0202221A3/hu unknown
- 2000-01-29 NZ NZ528077A patent/NZ528077A/en unknown
-
2001
- 2001-05-14 US US09/854,662 patent/US6596491B2/en not_active Expired - Fee Related
-
2002
- 2002-01-28 IL IL147872A patent/IL147872A/en not_active IP Right Cessation
- 2002-01-28 ZA ZA200200747A patent/ZA200200747B/xx unknown
- 2002-01-28 NO NO20020424A patent/NO20020424L/no not_active Application Discontinuation
- 2002-01-29 BG BG106361A patent/BG106361A/bg unknown
- 2002-02-28 HR HR20020186A patent/HRP20020186A2/hr not_active Application Discontinuation
-
2003
- 2003-01-24 HK HK03100657.1A patent/HK1048499B/zh not_active IP Right Cessation
- 2003-05-01 US US10/429,176 patent/US20040058884A1/en not_active Abandoned
-
2005
- 2005-12-13 US US11/300,662 patent/US20060105378A1/en not_active Abandoned
Non-Patent Citations (7)
| Title |
|---|
| ALL YOU WANTED TO KNOW ABOUT SELEX. kKLUG S J ET AL.MOLECULAR BIOLOGY REPORT, KLUWER ACADEMIC PUBLISHERS, DORDRECHT,Vol.20 No.2. 1994 |
| ALL YOU WANTED TO KNOW ABOUT SELEX. kKLUG S J ET AL.MOLECULAR BIOLOGY REPORT, KLUWER ACADEMIC PUBLISHERS, DORDRECHT,Vol.20 No.2. 1994 * |
| Biodistribution of 111IN-labelled SCN-bz-dtpa-sc-2 MAbfollwoing loco-regional injection info gliblastomas. MERLO A ET AL.International Journal of Cancer,Vol.71 . 1997 |
| Biodistribution of 111IN-labelled SCN-bz-dtpa-sc-2 MAbfollwoing loco-regional injection info gliblastomas. MERLO A ET AL.International Journal of Cancer,Vol.71. 1997 * |
| Inhibition of human angiogenin by DNA aptamers, Nuclearcolocalization of an angiogenin-inhibitor complex. NOBILE VALENTINA et al.BIOCHEMISTRY , AMERICAN CHEMICAL SOCIETY EASTON,Vol.37 No.19. 1998 |
| Inhibition of human angiogenin by DNA aptamers, Nuclearcolocalization of an angiogenin-inhibitor complex. NOBILE VALENTINA et al.BIOCHEMISTRY, AMERICAN CHEMICAL SOCIETY EASTON,Vol.37 No.19. 1998 * |
| Progress towards therapeutic application of Selex-DERIVEDAPTAMERS. POLISKY B.THE MANY FACES OF RNA. 1997 |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN100558411C (zh) | 腱生蛋白-c核酸配体 | |
| AU750820B2 (en) | Nucleic acid ligands of tissue target | |
| US5789157A (en) | Systematic evolution of ligands by exponential enrichment: tissue selex | |
| US5688935A (en) | Nucleic acid ligands of tissue target | |
| US6013443A (en) | Systematic evolution of ligands by exponential enrichment: tissue SELEX | |
| AU777043B2 (en) | Nucleic acid ligands to CD40ligand | |
| EP0823914B1 (en) | Systematic evolution of ligands by exponential enrichment: tissue selex | |
| ES2310695T3 (es) | Procedimientos para identificar y preparar ligandos de acido nucleico para tejidos. | |
| WO2001009157A1 (en) | High affinity vascular endothelial growth factor (vegf) receptor nucleic acid ligands and inhibitors | |
| US7005260B1 (en) | Tenascin-C nucleic acid ligands | |
| AU782620B2 (en) | High affinity vascular endothelial growth factor (VEGF) receptor nucleic acid ligands and inhibitors | |
| Ali | Selection of DNA aptamers against melanoma biomarkers |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 1075823 Country of ref document: HK |
|
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C17 | Cessation of patent right | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20091111 Termination date: 20100301 |
|
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: WD Ref document number: 1075823 Country of ref document: HK |