-
HINTERGRUND
DER ERFINDUNG
-
Die
vorliegende Erfindung betrifft die Sprachmodellierung. Insbesondere
betrifft die vorliegende Erfindung das Erzeugen eines Sprachmodells
für ein
Sprachverarbeitungssystem.
-
Eine
genaue Spracherkennung erfordert mehr als nur ein akustisches Modell,
um das korrekte Wort auszuwählen,
das von einem Benutzer gesprochen wird. In anderen Worten wird,
wenn ein Spracherkenner wählen
oder bestimmen muss, welches Wort gesprochen worden ist, wenn alle
Wörter
die gleiche Wahrscheinlichkeit aufweisen, gesprochen worden zu sein,
der Spracherkenner gewöhnlich
unzufriedenstellend arbeiten. Ein Sprachmodell stellt ein Verfahren
oder Mittel zum Spezifizieren davon zur Verfügung, welche Sequenzen von
Wörtern
in dem Wortschatz möglich
sind, oder liefert im allgemeinen Informationen über die Wahrscheinlichkeit
der verschiedenen Wortsequenzen.
-
Spracherkennung
wird häufig
als eine Form der Top-Down-Sprachverarbeitung angesehen. Zwei allgemeine
Formen der Sprachverarbeitung schließen „Top-Down" und „Bottom-Up" ein. Die Top-Down-Sprachverarbeitung
fängt mit
der größten Einheit
der Sprache an, die zu erkennen ist, wie ein Satz, und verarbeitet sie,
indem sie sie in kleinere Einheiten, wie Phrasen, klassifiziert,
die sodann in noch kleinere Einheiten, wie Wörter, klassifiziert werden.
Demgegenüber
fängt die
Bottom-Up-Sprachverarbeitung mit Wörtern an und bildet aus diesen
größere Phrasen
und/oder Sätze.
Beide Formen der Sprachverarbeitung können von einem Sprachmodell
profitieren.
-
Eine
allgemeine Technik des Klassifizierens besteht darin, eine formale
Grammatik zu verwenden. Die formale Grammatik definiert die Sequenz
von Wörtern,
die die Anwendung erlaubt. Eine bestimmte Art von Grammatik ist
als „kontextfreie
Grammatik" (CFG)
bekannt, die erlaubt, dass eine Sprache auf der Grundlage der Sprachstruktur
oder semantisch spezifiziert wird. Die CFG ist nicht nur leistungsfähig genug,
das meiste der Struktur in der gesprochenen Sprache zu beschreiben,
sondern ebenso hinreichend restriktiv, leistungsfähige Parser
zu haben. Dennoch ist die CFG, während
sie uns eine tiefere Struktur zur Verfügung stellt, noch nicht für eine Verarbeitung
gesprochener Sprache angebracht, da die Grammatik fast immer unvollständig ist. Ein
CFG- gegründetes System
ist nur gut, wenn man weiß,
welche Sätze
zu sprechen sind, was den Wert und die Brauchbarkeit des Systems
vermindert. Der Vorteil der strukturierten Analyse einer CFG wird
folglich in den meisten realen Anwendungen durch die schlechte Abdeckung
aufgehoben. Für
Anwendungsentwickler ist es auch häufig in hohem Grade arbeitsintensiv,
eine CFG zu kreieren.
-
Eine
zweite Form eines Sprachmodells ist ein N-Gram-Modell. Weil der
N-Gram mit einer großen
Menge Daten trainiert werden kann, kann die N-Wort-Abhängigkeit
eine syntaktische und semantische flache Struktur häufig nahtlos
aufnehmen. Es ist jedoch eine Vorbedingung dieses Ansatzes, dass
eine genügende Menge
an Trainingsdaten vorliegen muss. Das Problem für N-Gram-Modelle ist es, dass
eine große
Menge an Daten erforderlich ist und das Modell möglicherweise für die gewünschte Anwendung
nicht hinreichend spezifisch sein kann. Da ein wortgegründetes N-Gram-Modell
auf die N-Wort-Abhängigkeit
beschränkt
ist, kann es keine Bedingungen in der Sprache von längerer Reichweite
einschließen,
während
eine CFG dieses kann.
-
Ein
vereinheitlichtes Sprachmodell (eine Kombination von einem N-Gram
und von einer CFG enthalten) ist auch entwickelt worden. Das vereinheitlichte
Sprachmodell hat das Potential, die Schwächen sowohl des Wort-N-Gram-
als auch CFG-Sprachmodells zu überwinden.
Jedoch gibt es keinen klaren Weg, einen gebietsunabhängigen Trainingskorpus
oder gebietsunabhängige
Sprachmodelle, einschließlich
der vereinheitlichten Sprachmodelle, für gebietsspezifische Anwendungen
wirksam einzusetzen.
-
Es
gibt folglich ein fortwährendes
Bedürfnis,
neue Verfahren für
das Erzeugen von Sprachmodellen zu entwickeln. Während die Technologie sich
weiterentwickelt und Sprach- und Handschrifterkennung in mehr Anwendungen
zur Verfügung
gestellt wird, muss dem Anwendungsentwickler ein leistungsfähiges Verfahren zur
Verfügung
gestellt werden, in dem für
die ausgewählte
Anwendung ein passendes Sprachmodell erzeugt werden kann.
-
Gillett,
J. und Ward, W., „A
language model combining trigrams and stochastic contextfree grammars", ICSLP '98, 30. November
1998, Sydney, Australien, betrifft ein Sprachmodell, das ein Trigram-Models
mit einer stochastischen kontextfreien Grammatik (SCFG) kombiniert.
Das vorgeschlagene Klassen-Trigram-Modell spezifiziert jede Klasse
durch eine kontextfreie Grammatik, mit der Absicht, einfache Klassen
zu verwenden, die geradlinige Konzepte enthalten. Daher wird für jedes
Wort in dem Vokabular eine triviale Klasse definiert, und es werden
einheitliche Klassen-Trigram-Wahrscheinlichkeiten und einheitliche
Wahrscheinlichkeiten grammatikalischer Regeln zugewiesen. Für das Training
des Wort-Trigram-Modells sind aufgabenabhängige Korpora verwendet worden.
-
Kita,
K. et al., „Improvement
of a probabilistic CFG using a duster-based language modelling technique", 19, Oktober 1996,
betrifft das Einbeziehen von einem Clustering eines Trainingskorpus
in eine Anzahl von Sub-Korpora und dem darauffolgende Bestimmen
separater Wahrscheinlichkeitsverteilungen (probabilistische CFG)
aus jedem Sub-Korpus.
-
ZUSAMMENFASSUNG
DER ERFINDUNG
-
Es
ist das Ziel der Erfindung eine Verbesserung gegenüber einem
Klassen-Trigram-Sprachmodell
zur Verfügung
zu stellen.
-
Das
Ziel wird durch die vorliegende Erfindung, wie sie in den unabhängigen Ansprüchen beansprucht ist,
erreicht.
-
Bevorzugte
Weiterbildungen sind in den abhängigen
Ansprüchen
definiert.
-
Es
wird ein Verfahren für
das Erzeugen eines Sprachmodells aus einem aufgabenunabhängigen Korpus
zur Verfügung
gestellt. In einem ersten Aspekt wird ein aufgabenabhängiges vereinheitlichtes
Sprachmodell für
eine ausgewählte
Anwendung aus einem aufgabenunabhängigen Korpus erzeugt. Das
aufgabenabhängige
vereinheitlichte Sprachmodell schließt eingebettete Nonterminal-Zeichen
einer kontextfreien Grammatik in einem N-Gram-Modell ein. Das Verfahren
schließt
das Erhalten einer Mehrzahl von kontextfreien Grammatiken ein, die
Nonterminal-Zeichen umfassen, welche semantische oder syntaktische
Konzepte der Anwendung darstellen. Jede der kontextfreien Grammatiken
schließt
Wörter
oder Terminals ein, die in dem aufgabenunabhängigen Korpus vorhanden sind,
um die semantischen oder syntaktischen Konzepte zu bilden. Der aufgabenunabhängige Korpus
mit der Mehrzahl von kontextfreien Grammatiken wird geparst, um
Wortereignisse von jeder der semantischen oder syntaktischen Konzepte
und Phrasen zu identifizieren. Jedes der identifizierten Wortereignisse
wird durch entsprechende Nonterminal-Zeichen ersetzt. Ein N-Gram-Modell
wird gebildet, das die Nonterminal-Zeichen besitzt. Eine zweite Mehrzahl
von kontextfreien Grammatiken wird für mindestens einige der selben
Nonterminals erhalten, welche die selben semantischen oder syn taktischen
Konzepte darstellen. Jedoch ist jede der kontextfreien Grammatiken
der zweiten Mehrzahl für
den Gebrauch in der ausgewählten
Anwendung geeigneter.
-
Ein
zweiter Aspekt ist ein Verfahren für das Erzeugen eines aufgabenabhängigen vereinheitlichten Sprachmodells
für eine
ausgewählte
Anwendung aus einem aufgabenunabhängigen Korpus. Das aufgabenabhängige vereinheitlichte
Sprachmodell schließt
eingebettete Nonterminal-Zeichen einer kontextfreien Grammatik in
einem N-Gram-Modell
ein. Das Verfahren schließt
das Erhalten einer Mehrzahl von kontextfreien Grammatiken, die einen
Satz von kontextfreien Grammatiken hat, die Nonterminal-Zeichen haben, die
aufgabenabhängige
semantische oder syntaktische Konzepte darstellen, und mindestens
eine kontextfreie Grammatik, die ein Nonterminal-Zeichen für eine Phrase
hat, die mit einem der gewünschten
aufgabenabhängigen semantischen
oder syntaktischen Konzepte verwechselt werden kann, ein. Der aufgabenunabhängige Korpus mit
der Mehrzahl von kontextfreien Grammatiken wird geparst, um Wortereignisse
für jede
der semantischen oder syntaktischen Konzepte und der Phrasen zu
identifizieren. Jedes der identifizierten Wortereignisses wird durch
das entsprechende Nonterminal-Zeichen ersetzt. Ein N-Gram-Modell
wird sodann gebildet, das Nonterminal-Zeichen besitzt.
-
Ein
dritter Aspekt ist ein Verfahren für das Erzeugen eines Sprachmodells
für eine
ausgewählte
Anwendung aus einem aufgabenunabhängigen Korpus. Das Verfahren
schließt
das Erhalten einer Mehrzahl von kontextfreien Grammatiken, die Nonterminal-Zeichen
umfassen, welche semantische oder syntaktische Konzepte der ausgewählten Anwendung
darstellen, ein. Wortphrasen werden aus der Mehrzahl der kontextfreien Grammatiken
erzeugt. Die kontextfreien Grammatiken werden für die Formulierung einer Informationensuchabfrage
von mindestens einer der Wortphrasen verwendet. Der aufgabenunabhängige Korpus
wird auf der Grundlage der formulierten Abfrage abgefragt, und es
wird Text in dem aufgabenunabhängigen
Korpus auf der Grundlage der Abfrage identifiziert. Ein Sprachmodell
wird unter Verwendung des identifizierten Texts gebildet.
-
Ein
vierter Aspekt ist ein Verfahren für das Erzeugen eines Sprachmodells
für eine
ausgewählte
Anwendung aus einem aufgabenunabhängigen Korpus. Das Verfahren
schließt
das Erhalten einer Mehrzahl von kontextfreien Grammatiken, die Nonterminal-Zeichen
umfassen, welche semantische oder syntaktische Konzepte der ausgewählten Anwendung
darstellen, ein. Wortphrasen werden aus der Mehrzahl von kontextfreien Grammatiken
erzeugt. Ein erstes und ein zweites N-Gram-Sprachmodell wird aus
den Wortphra sen bzw. dem aufgabenunabhängigen Korpus gebildet. Das
erste N-Gram-Sprachmodell und das zweite N-Gram Sprachmodell werden
kombiniert, um ein drittes N-Gram-Sprachmodell zu bilden.
-
Ein
fünfter
Aspekt ist ein Verfahren für
das Erzeugen eines vereinheitlichten Sprachmodells für eine ausgewählte Anwendung
aus einem Korpus. Das Verfahren schließt das Erhalten einer Mehrzahl
von kontextfreien Grammatiken, die Nonterminal-Zeichen umfassen,
welche die semantischen oder syntaktischen Konzepte der ausgewählten Anwendung
darstellen, ein. Ein Wort-Sprachmodell wird aus dem Korpus gebildet. Wahrscheinlichkeiten
von Terminals von mindestens einigen der kontextfreien Grammatiken
werden normalisiert und als eine Funktion der entsprechenden Wahrscheinlichkeiten
zugewiesen, die für
die selben Terminals aus dem Wort-Sprachmodell erhalten werden.
-
KURZE BESCHREIBUNG
DER ZEICHNUNGEN
-
1 ist
ein Blockdiagramm eines Sprachverarbeitungssystems.
-
2 ist
ein Blockdiagramm einer beispielhaften Computerumgebung.
-
3 ist
ein Blockdiagramm eines beispielhaften Spracherkennungssystems.
-
4 ist
eine bildhafte Darstellung eines vereinheitlichten Sprachmodells.
-
5–8 sind
Flussdiagramme für
unterschiedliche Aspekte der vorliegenden Erfindung.
-
9 ist
ein Blockdiagramm eines anderen Aspekts der vorliegenden Erfindung.
-
AUSFÜHRLICHE BESCHREIBUNG DER BEISPIELHAFTEN
AUSFÜHRUNGSFORMEN
-
1 veranschaulicht
im Allgemeinen ein Sprachverarbeitungssystem 10, das eine
Spracheingabe 12 empfängt
und die Spracheingabe 12 verarbeitet, um eine Sprachausgabe 14 bereitzustellen.
Das Sprachverarbeitungssystem 10 kann z.B. durch ein Spracherkennungssystem
oder -modul verkörpert
werden, das als die Spracheeingabe 12 gesprochene oder
aufgezeichnete Sprache von einem Benutzer empfängt. Das Sprachverarbeitungssystem 10 verarbeitet
die gesprochene Sprache und stellt als eine Ausgabe erkannte Wörter gewöhnlich in
Form einer Textausgabe zur Verfügung.
-
Während der
Verarbeitung kann das Spracherkennungssystem oder -modul 10 auf
ein Sprachmodell 16 zugreifen, um zu bestimmen, welche
Wörter
gesprochen worden sind. Das Sprachmodell 16 kodiert eine bestimmte
Sprache, wie Englisch. In der veranschaulichten Ausführungsform
kann das Sprachmodell 16 ein N-Gram Sprachmodell oder ein
vereinheitlichtes Sprachmodell sein, das eine kontextfreie Grammatik,
die semantische oder syntaktische Konzepte mit Nonterminals spezifiziert,
und ein hybrides N-Gram-Modell
mit darin eingebetteten Nonterminals umfasst. Ein erweiterter Aspekt
der vorliegenden Erfindung ist ein Verfahren für das Erzeugen oder Bilden
des Sprachmodells 16 aus einem aufgabenunabhängigen Korpus,
von denen mehrere leicht verfügbar
sind, anstatt aus einem aufgabenabhängigen Korpus, der häufig schwer
zu erhalten ist.
-
Wie
von den Fachleuten erkannt, kann das Sprachmodell 16 in
anderen Sprachverarbeitungssystemen außer dem Spracherkennungssystem
benutzt werden, das oben besprochen wurde. Zum Beispiel können Sprachmodelle
der Art, die oben beschrieben wird, in der Handschriftenkennung,
in der optischen Zeichenerkennung (OCR), in der Rechtschreibprüfung, in
der Sprachübersetzung,
bei der Eingabe chinesischer oder japanischer Zeichen unter Verwendung
einer Standard-PC-Tastatur oder für die Eingabe englischer Wörter unter
Verwendung eines Telefontastaturblocks benutzt werden. Obgleich
sie unten besonders bezugnehmend auf ein Spracherkennungssystem
beschrieben wird, versteht es sich, dass die vorliegende Erfindung
für das
Bilden künstlicher
und natürlicher
Sprachmodelle in diesen und in anderen Formen der Sprachverarbeitungssysteme
nützlich
ist.
-
Vor
einer ausführlichen
Diskussion über
die vorliegende Erfindung, kann ein Überblick über eine Arbeitsumgebung nützlich sein. 2 und
die sich darauf beziehende Diskussion liefern eine kurze, allgemeine Beschreibung
einer geeigneten Computerumgebung, in der die Erfindung implementiert
werden kann. Obgleich es nicht erforderlich ist, wird die Erfindung
zumindest teilweise im allgemeinen Kontext computerausführbarer
Anweisungen, wie Programmmodulen, beschrieben, die von einem PC
ausgeführt
werden. Im Allgemeinen schließen
Programmmodule Routineprogramme, Objekte, Komponenten, Datenstrukturen,
etc. ein, die bestimmte Aufgaben durchführen oder bestimmte abstrakte
Datentypen implementieren. Aufgaben, die durch die Programme und
Module durchgeführt
werden, werden unten und mithilfe von Blockdiagramme und Flussdiagrammen beschrieben.
Die Fachleute können
die Beschreibungen, die Blockdiagramme und die Flussdiagramme als
prozessorausführbare
Anweisungen implementieren, die auf jede mögliche Form eines maschinenlesbaren
Datenträgers
geschrieben werden können.
Zusätzlich
werden die Fachleute erkennen, dass die Erfindung mit anderen Computersystemkonfigurationen,
einschließlich
Hand-Held-Vorrichtungen, Mehrprozessorsystemen, mikroprozessorgesteuerte
oder programmierbare Verbraucherelektronik, Netzwerk-PCs, Minicomputer,
Zentralrechner und dergleichen, ausgeführt werden kann. Die Erfindung
kann ebenso in verteilten Computerumgebungen ausgeführt werden,
in denen Aufgaben durch Remote-Verarbeitungsvorrichtungen ausgeführt werden,
die über
ein Kommunikationsnetz angeschlossen sind. In einer verteilten Computerumgebung
können
sich Programmmodule sowohl in lokalen als auch entfernten Speichervorrichtungen
befinden.
-
Mit
Bezug auf 2 schließt ein beispielhaftes System
für das
Implementieren der Erfindung eine universell verwendbare Computervorrichtung
in der Form eines herkömmlichen
PCs 50 ein, der eine Verarbeitungseinheit 51,
einen Systemspeicher 52 und einen Systembus 53,
der verschiedene Komponenten dieses System verbindet, wie auch den
Systemspeicher mit der Verarbeitungseinheit 51, ein. Der
Systembus 53 kann irgendeine von mehreren Arten von Busstrukturen,
einschließlich
eines Speicherbusses oder Speicherkontrollers, eines peripheren
Busses und eines lokalen Busse, sein, wobei irgendeine einer Vielzahl
von Busarchitekturen verwendet wird. Der Systemspeicher schließt einen
Festwertspeicher (ROM) 54 und einen wahlfreien Zugriffspeicher
(RAM) 55 ein. Ein grundlegendes Eingabe-/Ausgabe-System 56 (BIOS),
das die Basisroutine enthält,
die hilft, Informationen zwischen Elemente innerhalb des PCs 50,
wie während
des Startup, zu übermitteln,
wird in dem ROM 54 gespeichert. Der PC 50 schließt weiter
ein Festplattenlaufwerk 57 für das Lesen von und das Schreiben
auf eine Festplatte (nicht gezeigt), ein magnetisches Laufwerk 58 für das Lesen
von oder das Schreiben auf eine entnehmbare magnetische Disc 59 und
ein optisches Laufwerk 60 für das Lesen von oder das Schreiben
auf eine entnehmbare optische Disc, wie eine CD-ROM oder andere
optische Datenträger,
ein. Das Festplattenlaufwerk 57, das magnetische Laufwerk 58 und
das optische Laufwerk 60 werden durch eine Schnittstelle 62 des
Festplattenlaufwerks, eine Schnittstelle des magnetischen Laufwerks 63 bzw. eine
Schnittstelle des optischen Laufwerks 64 an den Systembus 53 angeschlossen.
Die Laufwerke und die entsprechenden maschinenlesbaren Datenträger stellen
permanente Speicher maschinenlesbarer Anweisungen, von Datenstrukturen,
von Programmmodule und anderer Daten für den PC 50 zur Verfügung.
-
Obgleich
die beispielhafte Umgebung, die hierin beschrieben wird, die Festplatte,
die entfernbare magnetische Disc 59 und die entfernbare
optische Disc 61 verwendet, sollte es von den Fachleuten
erkannt werden, dass andere Arten maschinell lesbarer Datenträger, die
Daten speichern können,
auf die ein Computer zugreifen kann, wie magnetische Kassetten,
Flash Memory Cards, digitale Videodiscs, Bernoulli-Patronen, wahlfreie
Zugriffsspeicher (RAMs), Festwertspeicher (ROM) und dergleichen
ebenso in der beispielhaften Arbeitsumgebung benutzt werden können.
-
Eine
Anzahl von Programmmodulen einschließlich eines Betriebssystems 65,
eines oder mehrerer Anwendungsprogramme 66, anderer Programmmodule 67 und
Programmdaten 68 kann auf der Festplatte, der magnetischen
Disc 59, der optischen Disc 61, dem ROM 54 oder
dem RAM 55 gespeichert werden. Ein Benutzer kann Befehle
und Informationen über
Eingabegeräte,
wie eine Tastatur 70, ein Handschrift-Tablet 71, eine
Zeigevorrichtung 72 und ein Mikrofon 92 in den
PC 50 eingeben. Andere Eingabegeräte (nicht gezeigt) können einen
Joystick, ein Game-Pad, eine Satellitenschüssel, einen Scanner oder dergleichen
einschließen. Diese
und andere Eingabegeräte
werden häufig
an der Verarbeitungseinheit 51 über eine serielle Schnittstelle 76 angeschlossen,
die mit dem Systembus 53 verbunden ist, aber sie können über andere
Schnittstellen, wie eine Soundkarte, einen parallelen Port, einen
Game-Port oder einen Universal Serial Bus (USB), angeschlossen werden.
Ein Monitor 77 oder eine andere Art eines Sichtanzeigegeräts wird
ebenso an den Systembus 53 über eine Schnittstelle, wie
einen Videoadapter 78, angeschlossen. Zusätzlich zu
dem Monitor 77 schließen PCs
gewöhnlich
andere periphere Ausgabevorrichtungen, wie einen Lautsprecher 83 und
einen Drucker (nicht gezeigt) ein.
-
Der
PC 50 kann "in
einer vernetzten Umgebung mit Logikanschlüssen zu einen oder mehreren
Remotecomputern, wie einem Remotecomputer 79, arbeiten.
Der Remotecomputer 79 kann ein anderer PC, ein Server,
ein Router, ein Netzwerk-PC, eine Peer-Vorrichtung oder ein anderer Netzwerkknoten
sein und schließt gewöhnlich viele
oder alle Elemente ein, die oben bezüglich eines PC 50 beschrieben
werden, obgleich nur eine Speicherspeichervorrichtung 80 in 2 veranschaulicht
werden ist. Die Logikanschlüsse,
die in 2 bildlich dargestellt werden, schließen ein
Local Area Network (LAN) 81 und ein Wide Area Network (WAN) 82 ein.
Solche Netzwerkumgebungen sind in Büros, unternehmenweite Computernetzwerk-Intranets
und dem Internet alltäglich.
-
Wenn
er in einer LAN-Netzwerkumgebung verwendet wird, wird der PC 50 an
das Local Area Network 81 durch eine Netzwerkschnittstelle
oder einen Adapter 83 angeschlossen. Wenn er in einer WAN-Netzwerkumgebung
verwendet wird, schließt
der PC 50 gewöhnlich
ein Modem 84 oder eine anderes Mittel für das Herstellen einer Kommunikation über das
Wide Area Network 82, wie das Internet, ein. Das Modem 84,
das intern oder extern sein kann, ist an den Systembus 53 über die
serielle Schnittstelle 76 angeschlossen. In einer Netzwerkumgebung
können
die Programmmodule, die im Verhältnis
zu dem PC 50 bildlich dargestellt werden, oder Teile davon,
in den entfernten Speichervorrichtungen gespeichert werden. Wie
von den Fachleuten erkannt wird, sind die Netzwerkverbindungen,
die gezeigt werden, beispielhaft, und andere Mittel des Hersiellens einer
Kommunikationsverbindung zwischen den Computern können verwendet
werden.
-
Eine
beispielhafte Ausführungsform
eines Spracherkennungssystems 100 wird in 3 veranschaulicht.
Das Spracherkennungssystem 100 schließt das Mikrofon 92,
einen Analog-Digital (A/D)-Wandler 104, ein Trainingsmodul 105,
ein Merkmalsextraktionsmodul 106, ein Lexikonspeichermodul 110,
ein akustisches Modell zusammen mit Senone-Bäumen 112,
eine Baumsuchmaschine 114 und das Sprachmodell 16 ein.
Es sollte bemerkt werden, dass das gesamte System 100 oder
ein Teil des Spracherkennungssystems 100 in der Umgebung
implementiert werden kann, die in 2 veranschaulicht
wird. Z.B. kann das Mikrofon 92 vorzugsweise als ein Eingabegerät zu dem
Computer 50 durch eine passende Schnittstelle und über den
A/D-Wandler zur Verfügung
gestellt werden. Das Trainingsmodul 105 und das Merkmalsextraktionsmodul 106 können entweder
Hardwaremodule in dem Computer 50 oder Software-Module
sein, die in irgendeiner der Informationsspeichervorrichtungen gespeichert
werden, die in 2 offenbart sind, und für die Verarbeitungseinheit 51 oder
einen anderen geeigneten Prozessor zugänglich sind. Zusätzlich werden
das Lexikonspeichermodul 110, das akustische Modell 112 und
das Sprachmodell 16 ebenso vorzugsweise in irgendeiner
der Speichervorrichtungen gespeichert, die in 2 gezeigt
werden. Des weiteren wird die Baumsuchmaschine 114 in der
Verarbeitungseinheit 51 implementiert (die eine oder mehrere
Prozessoren einschließen
kann) oder kann durch einen zugewiesenen Spracherkennungsprozessor
betrieben werden, der von dem PC 50 eingesetzt wird.
-
In
der veranschaulichten Ausführungsform
wird während
der Spracherkennung von einem Benutzer dem Mikrofon 92 Sprache
als Eingabe in das System 100 in der Form eines hörbaren Sprachsignals übermittelt.
Das Mikrofon 92 wandelt das hörbare Sprach signal in ein analoges
elektronisches Signal um, das dem A/D-Wandler 104 übermittelt
wird. Der A/D-Wandler 104 wandelt das analoge Sprachsignal
in eine Sequenz digitaler Signale um, die dem Merkmalsextraktionsmodul 106 übermittel
wird. In einer Ausführungsform
ist das Merkmalsextraktionsmodul 106 ein herkömmlicher
Vektorrechner, der eine spektrale Analyse der digitalen Signale
durchführt
und einen Absolutwert für
jedes Frequenzband eines Frequenzspektrums berechnet. Die Signale
werden in einer beispielhaften Ausführungsform dem Merkmalsextraktionsmodul 106 durch
den A/D-Wandler 104 mit
einer Abtastrate von ungefähr
16 kHz übermittelt.
-
Das
Merkmalsextraktionsmodul 106 teilt das digitale Signal,
das von dem A/D-Wandler 104 empfangen wird, in Frames,
die eine Mehrzahl von digitalen Samples einschließen. Jeder
Frame hat eine Dauer von ungefähr
10 Millisekunden. Die Frames werden dann durch das Merkmalsextraktionsmodul 106 in
einen Merkmalsvektor kodiert, der die spektralen Eigenschaften für eine Mehrzahl
von Frequenzbändern
wiedergibt. In dem Fall des separaten und halbkontinuierlichen Hidden-Markov-Modellierens
kodiert das Merkmalsextraktionsmodul 106 ebenso die Merkmalsvektoren
unter Verwendung von Vektorquantisierungstechniken und eines Codebuchs,
das aus Trainingsdaten hergeleitet wird, in eine oder mehrere Codewörter. Somit
stellt das Merkmalsextraktionsmodul 106 an seinem Ausgang
die Merkmalsvektoren (oder Codewörter)
für jede
gesprochene Äußerung zur
Verfügung.
Das Merkmalsextraktionsmodul 106 stellt die Merkmalsvektoren
(oder die Codewörter)
mit einer Rate von einem Merkmalsvektor oder (Codewort) ungefähr alle
10 Millisekunden zur Verfügung.
-
Ausgabewahrscheinlichkeitsverteilungen
werden sodann unter Verwendung des Merkmalsvektor (oder der Codewörter) des
bestimmten Frames, der geparst wird, gegen Hidden-Markov-Modelle
berechnet. Diese Wahrscheinlichkeitsverteilungen werden später verwendet,
wenn man eine Viterbi-Verarbeitung oder eine ähnliche Art der Verarbeitungstechnik
durchführt.
-
Nach
dem Empfangen der Codewörter
von dem Merkmalsextraktionsmodul 106 greift die Baumsuchmaschine 114 auf
Informationen zu, die in dem akustischen Modell 112 gespeichert
sind. Das Modell 112 speichert akustische Modelle, wie
Hidden-Markov-Modelle,
die die durch das Spracherkennungssystem 100 zu ermittelnden
Spracheinheiten darstellen. In einer Ausführungsform schließt das akustische
Modell 112 einen Senone-Baum ein, der mit jedem Markov-Zustand
in einem Hidden-Markov-Modell assoziiert ist. Die Hidden-Markov-Modelle
stellen in einer illustrativen Ausführungsform Phoneme dar. Auf
der Grundlage der Senone in dem akustischen Modell 112 bestimmt
die Baumsuchmaschine 114 die wahrscheinlichsten Phoneme,
die durch die Merkmalsvektoren (oder die Codewörter) dargestellt werden, die
von dem Merkmalsextraktionsmodul 106 empfangen werden,
und die folglich für
die Äußerung repräsentativ
sind, die von dem Benutzer des Systems empfangen wird.
-
Die
Baumsuchmaschine 114 greift ebenso auf das Lexikon zu,
das in Modul 110 gespeichert ist. Die Informationen, die
von der Baumsuchmaschine 114 basierend auf ihrem Zugriff
auf das akustische Modell 112 erhalten werden, werden bei
der Suche in dem Lexikonspeichermodul 110 verwendet, um
ein Wort zu bestimmen, das höchstwahrscheinlich
die Codewörter
oder den Merkmalsvektor darstellt, die von dem Merkmalsextraktionsmodul 106 empfangen
werden. Auch greift die Suchmaschine 114 auf das Sprachmodell 16 zu.
Das Sprachmodell 16 ist ein vereinheitlichtes Sprachmodell
oder ein Wort-N-Gram oder eine kontextfreie Grammatik, die für das Identifizieren
des wahrscheinlichsten Worts, das durch die Sprachgabe dargestellt
wird, verwendet wird. Das wahrscheinlichste Wort wird als Ausgabetext
zur Verfügung
gestellt.
-
Obgleich
hierin beschrieben wird, wie das Spracherkennungssystem 100 von
dem HMM Modellieren und den Senone-Bäumen Gebrauch macht, versteht
es sich, dass dieses nur eine illustrative Ausführungsform darstellt. Wie von
den Fachleuten erkannt wird, kann das Spracherkennungssystem 100 viele
Gestalten annehmen, und alles, was erforderlich ist, ist, dass es
das Sprachmodell 16 benutzt und als eine Ausgabe den Text
zur Verfügung
stellt, der von dem Benutzer gesprochen wird.
-
Wie
weithin bekannt ist, erzeugt ein statistisches N-Gram-Sprachmodell
eine Wahrscheinlichkeitsschätzung
für ein
Wort bei Vorgabe der Wortsequenz bis zu diesem Wort d.h. bei gegebener
Wortgeschichte H). Ein N-Gram-Sprachmodell betrachtet nur (n-1)
vorherige Wörter
in der Geschichte H als Einfluss auf die Wahrscheinlichkeit des
folgenden Wortes habend. Z.B. betrachtet ein Bigram- (oder 2-Gram-)
Sprachmodell das vorhergehende Wort als Einfluss auf das folgende
Wort habend. Folglich wird in einem N-Gram-Sprachmodell die Wahrscheinlichkeit
dafür,
dass ein Wort auftritt, wie folgt dargestellt: P(w/H) = P(w/w1, w2,... w(n-3)) (1) wobei w ein
interessierendes Wort ist, w1 das Wort ist, das sieh n-1 Positionen
n-1 vor dem Wort w befindet; w2 das Wort ist, das sich n-2 Positionen
vor dem Wort w befindet; und w(n-1) das erste Wort vor dem Wort
w in der Sequenz ist.
-
Auch
wird die Wahrscheinlichkeit einer Wortsequenz auf der Grundlage
der Multiplikation der Wahrscheinlichkeit jedes Wortes bei gegebener
Geschichte bestimmt. Folglich wird die Wahrscheinlichkeit für eine Wortsequenz
(w1 ... wm) wie folgt dargestellt:
-
Das
N-Gram-Modell wird erhalten, indem man einen N-Gram-Algorithmus
auf einen Korpus (eine Ansammlung von Phrasen, Sätzen, Satzfragmenten, Absätzen usw.)
von Texttrainingsdaten anwendet. Ein N-Gram-Algorithmus kann zum
Beispiel bekannte statistische Techniken, Katz's Technik oder der Binomial-Posterior-Verteilung-Backoff-Technik, verwenden.
Wenn er diese Techniken verwendet, schätzt der Algorithmus die Wahrscheinlichkeit,
dass ein Wort w (n) einer Sequenz der Wörter w1, w2,... w(n-1) folgt.
Diese Wahrscheinlichkeitswerte bilden zusammen das N-Gram-Sprachmodell.
Einige Aspekte der unten beschriebenen Erfindung können verwendet
werden, um ein statistisches N-Gram-Standardmodell zu bilden.
-
Wie
auch in dem Stand der Technik weithin bekannt ist, kann ein Sprachmodell
auch eine kontextfreie Grammatik enthalten. Eine kontextfreie Grammatik
liefert ein regelbasiertes Modell, das die semantischen oder syntaktischen
Konzepte der Satzstruktur oder der gesprochenen Sprache enthalten
kann. Zum Beispiel kann beispielsweise ein Satz kontextfreier Grammatiken
einer größeren Mehrzahl
von kontextfreien Grammatiken für
eine Software-Anwendung oder -aufgabe hinsichtlich der Festlegung
von Sitzungen oder des Sendens von elektronischen Nachrichten umfassen:
<Plane Sitzung> → <Planungsanweisung> <Sitzungsgegenstand>;
<Planungsanweisung> → buche;
<Planungsanweisung> → plane;
<Planungsanweisung> → setze an; etc.
<Sitzungsgegenstand> → Sitzung;
<Sitzungsgegenstand> → Abendessen;
<Sitzungsgegenstand> →Verabredung;
<Sitzungsgegenstand> → eine Sitzung mit <Person>;
<Sitzungsgegenstand> → ein Mittagessen mit <Person>;
<Person> → Anne Weber;
<Person> → Eric Moe;
<Person> → Paul Toman; etc.
-
In
diesem Beispiel bezeichnet „< >" Nonterminals für das Klassifizieren semantischer
oder syntaktischer Konzepte, wobei jedes der Nonterminals unter
Verwendung von Terminals (z.B. Wörter
oder Phrasen) und in einigen Fällen
anderer Nonterminal-Zeichen in einer hierarchischen Struktur definiert
ist.
-
Diese
Art der Grammatik erfordert kein eingehendes Wissen über die
formale Satzstruktur oder über die
Linguistik, sondern vielmehr ein Wissen davon, welche Wörter, Phrasen,
Sätze oder
Satzfragmente in einer bestimmten Anwendung oder Aufgabe verwendet
werden.
-
Ein
vereinheitlichtes Sprachmodell ist auch in dem Stand der Technik
weithin bekannt. Auf 4 bezugnehmend schließt ein vereinheitlichtes
Sprachmodell 140 eine Kombination eines N-Gram-Sprachmodells 142 und
einer Mehrzahl kontextfreier Grammatiken 144 ein. Genauer
schließt
das N-Gram-Sprachmodell 142 mindestens einige der selben
Nonterminals der Mehrzahl von kontextfreien Grammatiken 144 eingebettet
darin ein, so dass zusätzlich
zu dem Voraussagen von Wörtern,
das N-Gram-Sprachmodell 142 auch Nonterminals voraussagen
kann. Im Allgemeinen kann eine Wahrscheinlichkeit für ein Nonterminal
durch das folgende dargestellt werden: P(<NT>/h1, h2,... hn) (3)wobei (h1,
h2,... hn) vorhergehende Wörter
oder Nonterminals sein können.
Im Wesentlichen schließt
das N-Gram-Sprachmodell 142 (ebenso als ein hybrides N-Gram-Modell
bekannt) des vereinheitlichten Sprachmodells 140 ein vergrößertes Vokabular
ein, das Wörter
und mindestens einige der Nonterminals aufweist Im Gebrauch wird
das Spracherkennungssystem oder -modul 100 auf das Sprachmodell 16 (in
dieser Ausführungsform,
das vereinheitlichte Sprachmodell 140) zugreifen, um festzustellen,
welche Wörter
gesprochen worden sind. Das N-Gram-Sprachmodell 142 wird
benutzt, um zuerst Wörter
und Nonterminals vorauszusagen. Dann wird, wenn ein Nonterminal
vorausgesagt worden ist, die Mehrzahl von kontextfreien Grammatiken 144 verwendet,
um Terminals als Funktion der Nonterminals vorauszusagen. Jedoch
versteht es sich, dass die bestimmte Weise, in der das vereinheitlichte
Sprachmodell 140 benutzt wird, für die vorliegenden Erfindung
nicht kritisch ist.
-
Wie
in dem Hintergrundabschnitt erwähnt,
sollte dem Anwendungsentwickler ein leistungsfähiges Verfahren zur Verfügung gestellt
werden, in dem ein geeignetes Sprachmodell 16 für die ausgewählte Anwendung erzeugt
werden kann. In einigen Anwendungen arbeitet ein Standard-N-Gram-Sprachmodell
und alle mögliche Verbesserungen
für die
Entwicklung eines solchen Modells sind wertvoll. Während in
anderen Anwendungen ein vereinheitlichtes Sprachmodell 140 am
besten arbeiten mag, und dementsprechend Verbesserungen für das Bilden
eines solchen Modells auch wertvoll sind.
-
Während unterschiedliche
Anwendungen für
die Sprachverarbeitung entwickelt werden, können aufgabenabhängige (gebietabhängige) Sprachmodelle
wegen ihrer erhöhten
Spezifität,
durch die Sprachmodelle auch genauer gebildet werden können, geeigneter
als ein größeres, universelles
Sprachmodell sein. Es ist jedoch nicht so einfach, ein aufgabenabhängiges Sprachmodell
zu erzeugen, wie es ist ein universelles Sprachmodell zu erzeugen.
Um ein universelles Sprachmodell, wie ein N-Gram-Sprachmodell zu
erzeugen, kann ein aufgabenunabhängiger
Korpus von Trainingsdaten benutzt und wie oben besprochen für einen
N-Gram-Algorithmus verwendet werden. Aufgabenunabhängige Korpora
sind leicht verfügbar
und können
Kompilationen von Zeitschriften, Zeitungen, etc. enthalten, um nur
einige zu nennen. Die aufgabenunabhängigen Korpora zielen nicht
auf irgendeine Anwendung, sondern stellen eher viele Beispiele davon
zur Verfügung,
wie Wörter
in einer Sprache verwendet werden. Aufgabenabhängige Korpora sind auf der
anderen Seite gewöhnlich
nicht vorhanden. Diese Korpora müssen
mühsam
kompiliert werden und sind selbst dann möglicherweise nicht sehr vollständig.
-
Ein
erweiterter Aspekt der Erfindung schließt ein Verfahren für das Erzeugen
eines aufgaben- oder gebietsabhängigen
vereinheitlichten Sprachemodells für eine ausgewählte Anwendung
aus einem aufgabenunabhängigen
Korpus ein. Das aufgabenabhängige
vereinheitlichte Sprachmodell schließt eingebettete Nonterminal-Zeichen
der kontextfreien Grammatik in einem N-Gram-Sprachmodell ein. Wie
oben besprochen, ist der aufgabenunabhängige Korpus eine Kompilation
von Sätzen,
von Phrasen etc., die nicht auf irgendeine bestimmte Anwendung gerichtet
ist, sondern zeigt eher im Allgemeinen durch eine breite Vielzahl
von Beispielen, wie Wörter
in einer Sprache geordnet sind. Verschiedene Techniken, wie unten
beschrieben, sind entwickelt worden, um den aufgabenunabhängigen Korpus
für das
Erzeugen eines Sprachmodells zu benutzen, das für eine aufgabenabhängige Anwendung
verwendbar ist.
-
5 veranschaulicht
ein erstes Verfahren 160 für das Erzeugen oder das Bilden
eines Sprachmodells. Das Verfahren 160 schließt einen
Schritt 162 für
das Erhalten einer Mehrzahl von kontextfreien Grammatiken ein, die
Nonterminal-Zeichen umfassen, welche semantische oder syntaktischen
Konzepte darstellen. Wie hierin verwendet, schließt ein „semantisches
oder syntaktisches Konzept" ein
Wort oder Wortphrasen ein, die bestimmte Wortverwendungen für verschiedene
Befehle, Objekte, Tätigkeiten
etc. darstellen. Z.B. schließt der
aufgabenunabhängige
Korpus verschiedene Fälle
dafür ein,
wie Eigennamen verwendet werden. Z.B. könnte der aufgabenunabhängige Korpus
Sätze aufweisen
wie: „Bill
Clinton war bei der Sitzung anwesend" und "John Smith ging bei der Konferenz zu
Mittag essen". Obgleich
die Wörter,
die verwendet werden, um die semantischen oder syntaktischen Konzepte
in dem aufgabenunabhängigen
Korpus zu bilden, möglicherweise nicht
die sein können,
die für
die aufgabenabhängige
Anwendung verwendet werden, stellt der aufgabenunabhängige Korpus
verwendbare Beispiele zur Verfügung,
die den Kontext für
die semantischen oder syntaktischen Konzepte veranschaulichen. Der
Schritt 162 stellt das Erhalten von kontextfreien Grammatiken,
welche Non terminal-Zeichen aufweisen, um die semantischen oder syntaktischen
Konzepte in dem aufgabenunabhängigen
Korpus darzustellen, wobei die Nonterminal-Zeichen Terminals besitzen,
die in dem aufgabenunabhängigen
Korpus vorhanden sind. Zum Beispiel kann unter Verwendung des Eigennamenbeispiels,
das oben angegeben wurde, ein Beispiel für eine CFG das folgende sein:
<Person> → <Allgemeiner Vorname> [<Allgemeiner
Nachname>];
<Allgemeiner Vorname> → John|Bob|Bill...; (Vornamen,
die in dem aufgabenunabhängigen
Korpus vorhanden sind)
<Allgemeiner
Nachname> → Smith|Roberts|
Clinton...; (Nachnamen, die in dem aufgabenunabhängigen Korpus vorhanden sind).
-
Allgemein
wird eine Mehrzahl von kontextfreien Grammatiken, die Nonterminal-Zeichen
umfassen, die verschiedene semantische oder syntaktische Konzepte
darstellen, verwendet. Zum Beispiel schließen andere semantische oder
syntaktische Konzepte geographische Plätze, Regionen, Titel, Daten,
Zeiten, Währungsmengen
und prozentuale Anteile ein, um einige zu nennen. Jedoch versteht
es sich, dass diese semantischen oder syntaktischen Konzepte bloß illustrativ
sind und nicht für
das Ausüben
der vorliegenden Erfindung erforderlich sind, noch ist diese Liste
für alle
Arten von semantischen oder syntaktischen Konzepten, die stark von der
beabsichtigten Anwendung abhängen,
vollständig.
-
In
Schritt 164 wird der aufgabenunabhängige Korpus mit der Mehrzahl
der kontextfreien Grammatiken geparst, die in Schritt 162 erhalten
werden, um Wortereignisse in dem aufgabenuabhängigen Korpus aus jedem der
semantischen oder syntaktischen Konzepte zu identifizieren.
-
In
Schritt 166 wird jedes der identifizierten Wortereignisse
mit dem entsprechenden Nonterminal-Zeichen von Schritt 164 ersetzt.
Ein N-Gram-Modell wird dann in Schritt 168 unter Verwendung
eines N-Gram-Algorithmus gebildet, wobei das N-Gram-Modell die Nonterminal-Zeichen
darin eingebettet besitzt.
-
In
Schritt 170 wird eine zweite Mehrzahl von kontextfreien
Grammatiken, die für
die ausgewählte
Anwendung geeignet sind, erhalten. Insbesondere schließt die zweite
Mehrzahl von kontextfreien Grammatiken mindestens einige der selben
Nonterminal-Zeichen ein, welche die selben semantischen oder syntaktischen Konzepte
von Schritt 162 darstellen. Jedoch ist jede der kontextfreien
Grammatiken der zweiten Mehrzahl für die ausgewählte Anwendung
geeigneter. Mit Verweis auf das obige Eigennamenbeispiel könnte die
zweite Mehrzahl von kontextfreien Grammatiken eine CFG einschließen:
<Person> → <Name eines Angestellten der Titan Incorporated >;
<Name eines Angestellten
der Titan Incorporated > → XD|Ye-Yi|Milind|Xiaolong|...;
(Namen von Angestellten der Titan Incorporated).
-
Verfahren 160 kann
in einem Computer 50 implementiert sein, in dem jede der
kontextfreien Grammatiken und der aufgabenunabhängige Korpus auf irgendwelchen
der lokalen oder fernen Speichervorrichtungen gespeichert ist. Vorzugsweise
werden das N-Gram-Modell,
welches Nonterminal-Zeichen besitzt, und die zweite Mehrzahl von
kontextfreien Grammatiken, die Nonterminal-Zeichen haben, die aufgabenabhängige semantische
oder syntaktische Konzepte darstellen, auf einem maschinenlesbaren
Datenträger
gespeichert, der dem Spracherkenner 100 zugänglich ist.
-
6 veranschaulicht
ein Verfahren 180 für
das Erzeugen eines vereinheitlichten Sprachmodells für eine ausgewählte Anwendung
aus einem aufgabenunabhängigen
Korpus, der eine große
Anzahl an Phrasen einschließt,
die von unterschiedlichem Kontext sein können. Das einfache Parsen des
aufgabenunabhängigen Korpus
mit kontextfreien Grammatiken für
die aufgabenabhängige
Anwendung kann Fehler verursachen, die sich dann nach Anwendung
eines N-Gram-Algorithmus zu dem N-Gram-Modell fortpflanzen. Um die
Fehler während
des Parsens zu verringern, schließt dieser Aspekt der Erfindung
das Verwenden mindestens einer kontextfreien Grammatik ein, die
ein Nonterminal-Zeichen für
eine Phrase hat (Wort oder Wörter),
die mit einem der gewünschten
aufgabenabhängigen
semantischen oder syntaktischen Konzepte verwechselt werden kann.
Insbesondere wird in Schritt 182 eine Mehrzahl von kontextfreien
Grammatiken erhalten. Die Mehrzahl von kontextfreien Grammatiken
schließt
den Satz von kontextfreien Grammatiken, die Nonterminal-Zeichen haben,
die aufgabenabhängige
semantische oder syntaktische Konzepte (d.h. die semantischen oder
syntaktischen Konzepte, die die ausgewählte Anwendung direkt betreffen)
darstellen, und mindestens eine kontextfreie Grammatik, die ein
Nonterminal-Zeichen für
eine Phrase hat, die mit einem der gewünschten aufgabenabhängigen semantischen
oder syntaktischen Konzep te verwechselt werden kann, ein. Z.B. kann
eine aufgabenabhängige
Anwendung das Modellieren des Wochentags als ein semantisches Konzept
in dem N-Gram-Modell erfordern. Eine kontextfreie Grammatik der
folgenden Form könnte
während
des Parsens des aufgabenunabhängigen
Korpus verwendet werden:
<Tag> → Montag|Dienstag|..|Sonntag;
-
Der
aufgabenunabhängige
Korpus könnte
jedoch Bezüge
auf eine Person enthalten, die „Joe Freitag" genannt wird. Um
in diesem Fall „Freitag" als Nachnamen zu
behalten und um zu verhindern, dass dieser Fall als Tag geparst
wird, was sodann einen Fehler in das N-Gram-Modell einführen würde, kann
die Mehrzahl von kontextfreien Grammatiken eine kontextfreie Grammatik
der Form einschließen:
<Person mit Nachnamen
Feitag> → (Joe|Bill|Bob...)
Freitag;
(verschiedene Vornamen, die den Nachnamen „Freitag„ haben).
-
Auf
diese Weise werden während
des Parsens des aufgabenunabhängigen
Korpus Fälle
von Wochentagen getrennt von Fällen
identifiziert, in denen „Freitag" der Nachname einer
Einzelperson ist.
-
Schritt 184 stellt
das Parsen des aufgabenunabhängigen
Korpus mit der Mehrzahl von kontextfreien Grammatiken dar, um Wortereignisse
für jedes
der semantischen oder syntaktischen Konzepte zu identifizieren.
In Schritt 186 wird jedes der identifizierten Wortereignisse
für Nonterminals,
die Konzepte darstellen, die für
die Zielanwendung von Interesse sind, mit dem entsprechenden Nonterminal-Zeichen
ersetzt, wie es durch die entsprechende kontextfreie Grammatik definiert
ist. In anderen Worten werden die Wortsequenzen, die mit den externen
Nonterminals identifiziert werden, die eingeführt wurden, um Analysefehler
zu verhindern (wie <Person
mit Nachnamen Freitag> in
dem obigen Beispiel), nicht durch das entsprechende Nonterminal
ersetzt. Ein N-Gram-Modell kann dann gebildet werden, das die Nonterminal-Zeichen
darin eingebettet aufweist, wie es in Schritt 188 gezeigt
ist. Schritt 190 ist Schritt 170 ähnlich und
schließt
das Erhalten eines zweiten Satzes kontextfreier Grammatiken ein,
die für
die ausgewählte
Anwendung geeignet sind.
-
Verwendet
während
der Sprachverarbeitung wie Spracherkennung ist das N-Gram-Modell, welches die
Nonterminal-Zeichen und die Mehrzahl von kontextfreien Grammatiken
assoziiert mit der aufgabenabhängigen
Anwendung hat, auf einem maschinenlesbaren Datenträger gespeichert,
der für
das Spracherkennungsmodul 100 zugänglich ist. Jedoch ist es nicht
notwendig, die kontextfreien Grammatiken einzuschließen, die mit
den Phrasen assoziiert sind, die mit einer der gewünschten
aufgabenabhängigen
semantischen oder syntaktischen Konzepte verwechselt werden können, weil
diese kontextfreien Grammatiken nur verwendet werden, um den aufgabenunabhängigen Korpus
richtig zu parsen. Die Phrasen, die mit diesen Grammatiken assoziiert
sind, würden
normalerweise nicht in der ausgewählten Anwendung gesprochen
werden. Somit ist der Umfang oder die Größe einer Mehrzahl von kontextfreien
Grammatiken während
der Spracherkennung kleiner, was einem geringeren erforderlichen
Speicherplatz in dem Computer 50, als er für das Parsen
des aufgabenunabhängigen
Korpus verwendet wurde, entspricht.
-
In
einer Ausführungsform
kann der Schritt 188, der mit dem Bilden des N-Gram-Modells
assoziiert ist, das Enstfernen mindestens einiger Teile von dem
assoziierten Text aus dem aufgabenunabhängigen Korpus für Nonterminal-Zeichen
einschließen,
die mit einem der gewünschten
aufgabenabhängigen
semantischen oder syntaktischen Konzepte verwechselt werden können. Auf
diese Weise wird die Größe des aufgabenunabhängigen Korpus
vor dem Parsen verringert, so dass das Verfahren 180 schneller
durchgeführt
werden kann.
-
Es
sollte auch bemerkt werden, dass das Verfahren 180 einen
zusätzlichen
Schritt des Überprüfens des
geparsten aufgabenunabhängigen
Korpus oder des resultierenden N-Gram-Modells
einschließen
kann, um Fehler wegen der Phrasen (Wort oder Wörter) zu ermitteln, die mit
einer der gewünschten
aufgabenabhängigen
semantischen oder syntaktischen Konzepte verwechselt werden. Geeignete
kontextfreie Grammatiken können
sodann in der Mehrzahl der kontextfreien Grammatiken in Schritt 182 festgestellt
und eingeschlossen werden. Schritte 184 bis 188 können dann
falls erforderlich durchgeführt
werden, um den geparsten aufgabenunabhängige Korpus- oder das N-Gram-Modell
nochmals zu prüfen,
um zu emritteln, ob die Fehler behoben worden sind. Dieser iterative
Prozess kann falls erforderlich wiederholt werden, bis die Fehler
behoben sind, und ein geeignetes N-Gram-Modell erhalten worden ist.
-
Wie
oben besprochen, ist der aufgabenunabhängige Korpus ein allgemeiner
Korpus und tatsächlich ist
es wahrscheinlich, dass der größte Teil
des Korpus keinen Bezug zu der Aufgabe oder zu der Anwendung hat,
an der der Entwickler interessiert ist. Dennoch kann der aufgabenunabhängige Korpus
etwas Text enthalten, der für
die Aufgabe oder die Anwendung relevant ist. Im Allgemeinen schließt ein anderer
Aspekt der vorliegenden Erfindung die Verwendung der kontextfreien
Grammatiken für
die aufgabenabhängige
Anwendung, um Phrasen, Sätze
oder Satzfragmente zu bilden, ein, die dann als Abfragen in einem
Informationsabfrage-System benutzt werden können. Das Informationsabfrage-System überprüft den aufgabenunabhängigen Korpus
und identifiziert die Teile, die der Abfrage ähnlich sind. Der identifizierte
Text des aufgabenunabhängigen
Korpus ist für
die ausgewählte
Aufgabe oder Anwendung relevanter; folglich kann ein Sprachmodell,
das aus dem identifizierten Text abgeleitet wird, spezifischen sein
als ein Sprachmodell, das auf dem vollständigen aufgabenunabhängigen Korpus
basiert. Hinzu kommt, dass, obgleich jemand, der sich in der spezifischen
Aufgabe aller Anwendung auskennt, die kontextfreien Grammatiken
schrieb, er nicht alle verschiedenen Wortsequenzen kennen kann,
die für
die Aufgabe oder die Anwendung verwendet werden können. Diese
Technik verengt den aufgabenunabhängige Korpus, aber sie kann
dennoch mehr Beispiele von aufgabenspezifischen Sätze, Phrasen,
etc. identifizieren.
-
7 veranschaulicht
ein Verfahren 200 für
das Erzeugen eines Sprachmodells für eine ausgewählte Anwendung
aus einem aufgabenunabhängigen
Korpus in der Weise, die oben besprochen wurde. Schritt 202 schließt das Erhalten
einer Mehrzahl von kontextfreien Grammatiken ein, die Nonterminal-Zeichen
umfassen, welche die semantischen oder syntaktischen Konzepte der
ausgewählten
Anwendung darstellen. Wie oben beschrieben, werden die kontextfreien
Grammatiken allgemein von einem Entwickler geschrieben, der mindestens
einiges Wissen darüber
hat, welche Phrasen in der ausgewählten Anwendung für jedes
der semantischen oder syntaktischen Konzepte verwendet werden können, jedoch
ist der Umfang des Wissens über
solche Phrasen nicht vollständig.
In Schritt 204 werden Wortphrasen aus der Mehrzahl von
kontextfreien Grammatiken erzeugt. Die Wortphrasen können einige
oder alle der verschiedenen Kombinationen und Permutationen einschließen, die
durch die assoziierten kontextfreien Grammatiken definiert werden,
in denen Nonterminal-Zeichen mehrere Wörter einschließen.
-
In
Schritt 206 wird mindestens eine Anfrage für ein Informationsabfrage-System
unter Verwendung mindestens einer der erzeugten Wortphrasen formuliert.
Die Abfrage kann unter Verwendung einer Technik eines statistischen "Beutels von Wörtern" erzeugt wer den,
die TF-IDF Vektoren verwendet. Eine Ähnlichkeit zwischen der Anfrage
und den Segmenten des aufgabenunabhängigen Korpus kann methilfe
des Kosinusähnlichkeitsmaßes berechnet
werden. Dieses sind im Allgemeinen weithin bekannte Techniken auf
dem Gebiet der Informationsabfrage. Alternativ kann die Abfrage
Boolesche Logik („und", „oder", etc.) einschließen, wie
es erwünscht
ist, um Wortphrasen zu kombinieren. Jedoch könnte jede Anfrage einfach eine
separate Wortphrase sein, wie es von den Fachleuten erkannt wird.
-
In
Schritt 208 wird der aufgabenunabhängige Korpus auf der Grundlage
der formulierten Abfrage abgefragt. Die bestimmte Informationsanfrage
-Technik, die verwendet wird, um die Abfrage des aufgabenunabhängigen Korpus
zu erzeugen und durchzuführen,
ist für
dieses Merkmal der vorliegenden Erfindung nicht kritisch. Vielmehr
kann jede geeignete Abfrageentwicklung und Informationsabfrage-Technik
verwendet werden. Es sollte einfach bemerkt werden, dass das Sprachmodell,
das aus dem identifizierten Text entsprechend der vorliegenden Technik
erzeugt wird, besser mit Informationsabfrage-Techniken arbeitet,
die relevanteren Text des aufgabenunabhängigen Korpus identifizieren.
-
Der
Text, der in dem aufgabenunabhängigen
Korpus basierend auf der Anfrage identifiziert wird, wird in Schritt 210 angezeigt.
Sodann kann ein Sprachmodell mit dem identifizierten Text gebildet
werden, wie es in Schritt 212 dargestellt ist.
-
An
diesem Punkt sollte bemerkt werden, dass das Verfahren, das in 7 veranschaulicht
wird, nicht auf ein vereinheitlichtes Sprachmodell oder gar ein
N-Gram-Sprachmodell beschränkt
ist, sondern dass es eher nützlich
sein kann, wenn Sprachmodelle irgendeiner Art gebildet werden, die
in einem Sprachverarbeitungssystem benutzt werden, in dem das Modell
auf einem aufgabenunabhängigen
Korpus basiert. Dennoch ist das Verfahren 200 besonders
nützlich,
wenn man ein N-Gram-Sprachmodell bildet. In dem Fall eines N-Gram
Sprachmodells oder eines hybriden N-Gram-Sprachmodells erfordert
Schritt 212 allgemein die Verwendung von einem N-Gram-Algorithmus.
-
8 veranschaulicht
ein Verfahren 220, das dem Verfahren 200 von 7 ähnlich ist,
worin die selben Bezugszeichen verwendet worden sind, um gleiche
Schritte zu kennzeichnen. Das Verfahren 220 kann jedoch
verwendet werden, um ein N-Gram-Sprachmodell zu erzeugen, welches
die Nonterminal-Zeichen der kontextfreien Grammatiken hat. Zusätzlich zu
den Schritten, die oben beschrieben werden, schließt das Verfahren 220 auch
das Parsen des identifizierten Textes des aufgabenunabhängigen Korpus
mit einer Mehrzahl von kontextfreien Grammatiken ein, um Wortereignisse
für jedes
der semantischen oder syntaktischen Konzepte zu identifizieren,
wie es in Schritt 222 angegeben ist. Schritt 224 schließt dann
das Ersetzen jedes des identifizierten Wortereignisses mit entsprechendem
Nonterminal-Zeichen für
ausgewählte
Nonterminals ein (d.h. ausschließlich der Nonterminals, die
eingeführt
worden sein können,
um Fehler während
des Parsens zu verhindern). Schritt 212 würde dann
das Bilden eines N-Gram-Modells einschließen, das Nonterminal-Zeichen besitzt.
In beiden Verfahren 200 und 220 wird der relevante
Text in dem aufgabenunabhängigen
Korpus identifiziert. Wenn es gewünscht wird, kann der identifizierte
Text getrennt von dem aufgabenunabhängigen Korpus als ein Hilfsmittel
für das
Isolieren des relevanten Textes und eine einfachere Verarbeitung
zur Verfügung
stellend extrahiert, kopiert oder anderweitig gespeichert werden.
-
9 ist
ein Blockdiagramm, das einen anderen Aspekt der vorliegenden Erfindung
veranschaulicht. Im Allgemeinen schließt dieser Aspekt die Bildung
eines N-Gram-Sprachmodells
aus den Wortphrasen, die von den kontextfreien Grammatiken erhalten
werden, und das Kombinieren des N-Gram-Sprachmodells mit einem anderen
N-Gram- Sprachmodell,
das auf dem aufgabenunabhängigen
Korpus basiert, ein. In der Ausführungsform,
die in 9 veranschaulicht wird, stellt Block 240 die
kontextfreien Grammatiken dar, die für die ausgewählte Aufgabe
oder die Anwendung erhalten werden (z.B. von dem Entwickler geschrieben
sind). Die kontextfreien Grammatiken werden verwendet, um synthetische
Daten oder Wortphrasen 242 auf eine Weise zu erzeugen,
die dem Schritt 204 der Verfahren 200 und 220 ähnlich ist.
Die Wortphrasen 242 werden dann einem N-Gram-Algorithmus 244 übergeben,
um ein erstes N-Gram-Sprachmodell 246 zu bilden.
-
9 veranschaulicht
ebenso in Blockdiagrammform Schritte 206, 208 und 210,
in denen die kontextfreie Grammatiken verwendet werden, um eine
Informationensuchabfrage aus mindestens einer der Phrasen zu formulieren,
den aufgabenunabhängige
Korpus auf der Grundlage der formulierten Abfrage abzufragen, den
assoziierten Text in dem aufgabenunabhängigen Korpus auf der Grundlage
der Abfrage zu identifizieren und ein zweites N-Gram-Sprachmodell
aus dem identifizierten Text zu bilden. Block 248 veranschaulicht
die Anwendung eines N-Gram-Algorithmus, um das zweite N-Gram-Sprachmodell 250 zu
erhalten.
-
Ein
drittes N-Gram-Sprachmodell 252 wird gebildet, indem man
das erste N-Gram-Sprachmodell 246 und
das zweite N-Gram-Sprachmodell 250 kombiniert. Diese Kom bination
kann mit jeder möglichen
bekannten Glättungstechnik,
wie Interpolation, gelöschte
Interpolation oder irgendeiner anderen geeigneten Technik, durchgeführt werden.
Wenn es gewünscht
wird, kann das zweite Sprachmodell gegründet darauf gewichtet werden,
ob angenommen wird, dass der identifizierte Text genau ist. Das
Gewichten kann auf der Menge des identifizierten Textes in dem aufgabenunabhängigen Korpus,
der Zahl der verwendeten Abfragen etc. basieren.
-
In
einer anderen Ausführungsform
können
die Nonterminal-Zeichen, welche die semantischen oder syntaktischen
Konzepte darstellen, in den identifizierten Text oder in den aufgabenunabhängigen Korpus
eingefügt
werden, so dass das zweite N-Gram-Sprachmodell Nonterminal-Zeichen einschließt. Diese
Option wird mithilfe der gestrichelten Linien für Block 264 und der
Pfeile 266 und 268 veranschaulicht. Selbstverständlich würde, wenn
diese Option gewählt
wird, der identifizierte Text 210 nicht direkt dem N-Gram-Algorithmus 248, sondern
eher dem Block 264 übergeben.
Die Nonterminal-Zeichen,
die in den identifizierten Text oder in den aufgabenunabhängigen Korpus
eingefügt
werden, können
auf den kontextfreien Grammatiken, die in Block 240 erhalten
werden, oder alternativ auf einem anderen Satz von kontextfreien
Grammatiken 270, der andere kontextfreie Grammatiken aus
den Gründen
einschließt,
die oben besprochen wurden, basieren. Wenn das dritte N-Gram-Sprachmodell 252 gebildet
wird, das Nonterminals besitzt, schließen die Wortphrasen oder die synthetischen
Daten in Block 242 typischer Weise ebenfalls die Nonterminals
ein.
-
Wenn
die kontextfreien Grammatiken verwendet werden, um synthetische
Daten zu erzeugen, können Wahrscheinlichkeiten
für die
Wortphrasen, die mit den Nonterminals und den Terminals der Nonterminals
gebildet werden, ausgewählt
werden, wie es erwünscht
ist; zum Beispiel kann jeder die gleiche Wahrscheinlichkeit zugewiesen
werden.
-
Das
aufgabenabhängige
vereinheitlichte Sprachmodell schließt eingebettete Nonterminal-Zeichen
der kontextfreien Grammatik in einem N-Gram sowie eine Mehrzahl
von kontextfreien Grammatiken ein, die die Nonterminal-Zeichen definieren.
Innerhalb jeder kontextfreien Grammatik kann die probabilistische
kontextfreie Standardgrammatik verwendet werden. Ohne reale Daten
betreffend die spezifische Aufgabe oder Anwendung kann jedoch eine
Schätzung
für jede
der Terminalwahrscheinlichkeiten nicht leicht bestimmt werden. In
anderen Worten kann der Entwickler die Mehrzahl von kontextfreien
Grammatiken schreiben oder anders erhalten; eine Schätzung der
Wahrscheinlichkeiten für
jedes der Terminals kann jedoch nicht leicht erfolgen. Obgleich
eine gleichförmige Verteilung
von Wahrscheinlichkeiten verwendet werden kann, schließt ein anderer Aspekt
der vorliegenden Erfindung das Zuweisen von Wahrscheinlichkeiten
zu Terminals von mindestens einigen der kontextfreien Grammatiken
als eine Funktion der entsprechenden Wahrscheinlichkeiten ein, die
für die
selben Terminals von dem N-Gram-Sprachmodell
erhalten werden, das aus dem aufgabenunabhängigen Korpus gebildet wird.
Vorzugsweise schließt
das Zuweisen von Wahrscheinlichkeiten zu Terminals der kontextfreien
Grammatiken das Normalisieren der Wahrscheinlichkeiten der Terminals
aus dem N-Gram-Sprachmodell in jeder der kontextfreien Grammatiken
als eine Funktion der Terminals in der entsprechenden kontextfreien
Grammatik ein. In anderen Worten begrenzt oder definiert die kontextfreie
Grammatik den zulässigen
Satz von Terminals von dem N-Gram-Sprachmodell. Folglich müssen Wahrscheinlichkeiten
der Terminals von dem N-Gram-Sprachmodell in dem selben Wahrscheinlichkeitsraum
wie die Terminals in der entsprechenden kontextfreien Grammatik
geeignet normalisiert werden.
-
In
einer Ausführungsform
kann eine Eingabeäußerung W
= w
1 w
2...w
S in eine Sequenz T = t
1 t
2... t
m, segmentiert
werden, in der jedes t
i entweder ein Wort
in W oder ein Nonterminal einer kontextfreien Grammatik ist, das
eine Sequenz von Wörtern
in W umfasst. Die Wahrscheinlichkeit
von W unter der Segmentation T ist folglich
-
Zusätzlich zu
den Trigram-Wahrscheinlichkeiten müssen wir
mit einbeziehen, die Wahrscheinlichkeit
des Erzeugens einer Wortsequenz
aus dem Nonterminal t
i der kontextfreien Grammatik. In dem Fall,
in dem t
i selbst ein Wort ist
Andernfalls kann
erhalten werden, indem man
jedes Wort in der Sequenz aufgrund seiner Wortgeschichte vorhersagt:
-
Hierbei
stellt </s> das spezielle Ende-der-Sequenz-Wort
dar. Drei unterschiedliche Verfahren werden verwendet, um die Wahrscheinlichkeit
eines Wortes bei gegebener Geschichte innerhalb eines Nonterminals einer
kontextfreien Grammatik zu berechnen.
-
Eine
Geschichte
entspricht einem Satz Q (h),
wobei jedes Element in dem Satz ein CFG-Zustand ist, der die I-1
Anfangswörter in
der Geschichte von dem Nonterminal t
i erzeugt.
Ein CFG-Zustand begrenzt die möglichen
Wörter,
die der Geschichte folgen können.
Die Vereinigung der Wortsätze
für alte
CFG-Zustände
in Q (h), W
Q(h), definiert alle zugelassenen
Wörter
(einschließlich
des Symbols „</s>" für
das Verlassen des Nonterminals t
i, wenn
die der Geschichte entsprechend
den Bedingungen der kontextfreien Grammatik folgen können. Die
Wahrscheinlichkeit, u
t,1 nach der Geschichte
zu beobachten, kann durch die gleichförmige Verteilung unten geschätzt werden:
-
Das
gleichförmige
Modell enthält
nicht die empirische Wortverteilung unter einem Nonterminal einer kontextfreien
Grammatik. Eine bessere Alternative besteht darin, vorhandene gebietsunabhängige Wort-Trigram-Wahrscheinlichkeiten
zu übernehmen.
Diese Wahrscheinlichkeiten müssen
in dem selben Wahrscheinlichkeitsraum geeignet normalisiert werden.
Obwohl wir Wort-Trigram-Modelle verwendet haben, um die Technik
zu veranschaulichen, sollte bemerkt werden, dass irgendein wortbasiertes
Sprachmodell, einschließlich Wortniveau-N-Grams
mit unterschiedlichem N, hier verwendet werden können. Auch ist die Technik
anwendbar ungeachtet, wie die Wort-Sprachmodelle trainiert werden
(insbesondere ob ein aufgabenunabhängiger oder aufgabenabhängiger Korpus
benutzt wird). Somit erhalten wir:
-
Eine
andere Art, das Modellieren einer Wortsequenz zu verbessern, die
von einem spezifischen CFG-Nonterminal umfasst wird, besteht darin,
ein spezifisches Wort-Trigram-Sprachmodell
Pt(wn|wn-2,
wn-1) für jedes
Nonterminal t zu benutzen. Die Normalisierung wird wie in Gleichung
(7) durchgeführt.
-
Es
können
wegen der Mehrdeutigkeit der natürlichen
Sprache mehrere Segmentationen für
W vorhanden sein. Die Wahrscheinlichkeit von W ist folglich die
Summe über
alle Segmentationen S(W):
-
Obgleich
die vorliegende Erfindung mit Bezug auf bevorzugte Ausführungsformen
beschrieben worden ist, erkennen die Fachleute, dass Änderungen
in Form und Details vorgenommen werden können, ohne den Bereich der
Erfindung zu verlassen.



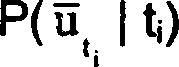 aus dem Nonterminal ti der kontextfreien Grammatik. In dem Fall, in dem ti selbst ein Wort ist
aus dem Nonterminal ti der kontextfreien Grammatik. In dem Fall, in dem ti selbst ein Wort ist Andernfalls kann
Andernfalls kann erhalten werden, indem man jedes Wort in der Sequenz aufgrund seiner Wortgeschichte vorhersagt:
erhalten werden, indem man jedes Wort in der Sequenz aufgrund seiner Wortgeschichte vorhersagt:

 die der Geschichte entsprechend den Bedingungen der kontextfreien Grammatik folgen können. Die Wahrscheinlichkeit, ut,1 nach der Geschichte zu beobachten, kann durch die gleichförmige Verteilung unten geschätzt werden:
die der Geschichte entsprechend den Bedingungen der kontextfreien Grammatik folgen können. Die Wahrscheinlichkeit, ut,1 nach der Geschichte zu beobachten, kann durch die gleichförmige Verteilung unten geschätzt werden:


